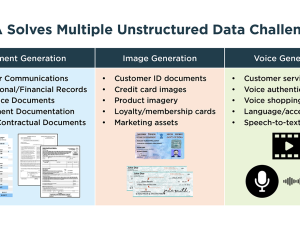
5 Ways to Get Started Using Synthetic Test Data
Choose Your Starting Point: 5 Ways to Utilize Synthetic Test Data with GenRocket
Dev & test is under constant pressure to quickly develop and test new code. They’re accustomed to using production data copies as a solution for their test data or writing scripts, manually creating, or using spreadsheets as their method of data creation.
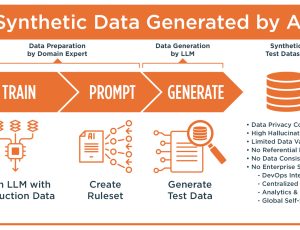
Many testers are unaware of how much a synthetic data platform like GenRocket can speed up their testing process and how to get started with synthetic data. With GenRocket, test data is always generated with referential integrity, based on rules & conditions, and can be generated in just about any volume, variety and format.
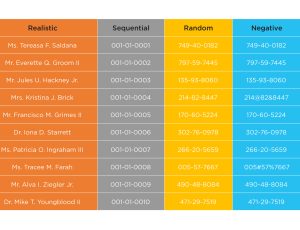
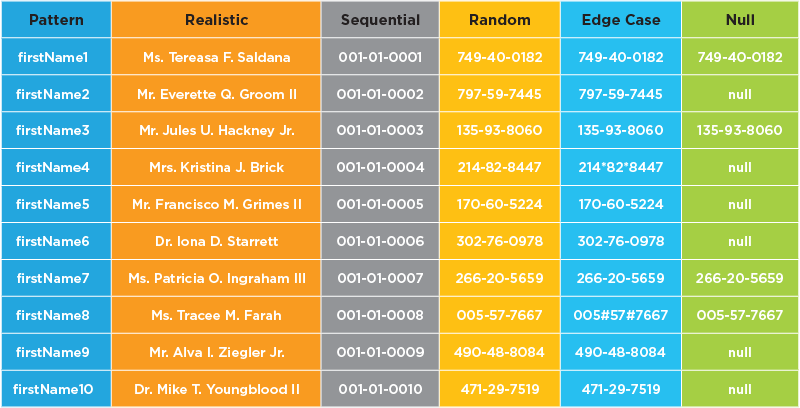
For some functional tests the data should look realistic, but for many use cases, patterned and sequential data, which guarantees uniqueness, is better for load and performance testing. And with synthetic data it’s easy to control data for negative and edge case test cases. See some synthetic data examples below:
So the first question with synthetic data is often “is it worth my time” and the short answer is “yes” because the time savings are huge as well as the impact on quality. For example, in one customer project, GenRocket reduced test time from 25 hours per cycle to 5 to 10 minutes. For another customer project, GenRocket reduced cycle time from 40 hours down to 2 hours.
So, now the question is “How should I get started with synthetic data?” To address this frequently asked question by our customers, we’ve put together five suggestions for Devops teams to get started using synthetic test data.
1. Slow production data copy provisioning time (or using manual / spreadsheet data creation methods)
One way to immediately experience GenRocket’s benefits is to begin with a test data challenge where data provisioning is slow. Production data reflects certain rules and conditions of the production environment, but often data that follows very specific rules & conditions can’t be found in production copies. In these cases the data is created manually or in spreadsheets. This is where synthetic test data automation can dramatically speed up data provisioning.
2. Tests with low coverage (under 20% coverage)
Is there a particular use case that is challenging to address with your existing test data environment? If your dev & test teams are unable to find enough volume and variety of data to do negative and edge case testing for boundary conditions, GenRocket may be a great way to increase coverage. Our customers tell us that only 2% to 3% of test data sourced from production offers edge case values, so manually created data is often required for such testing. The same is true for negative data or testing an application with a large combination of input values. Tests with low coverage (under 20%) can easily be changed into 80% to 90% coverage or more using GenRocket.
3. High volume data requirements (millions of rows) or more transactions
If you have projects that require millions of rows of data or lack the volume of transactional data, this is another area where GenRocket can help. The platform can generate the volume of synthetic test data required for large, enterprise-wide tests in a matter of minutes versus the hours and days it would take to manually provision such data. And GenRocket can easily generate transactions in the past, present or future. GenRocket high volume data generation is ideal for enterprise-wide testing of ‘big data’ projects where more data is needed than is available in production copies.
4. Most frequent test procedures (time savings are compounded)
Do you have a test procedure that needs to run frequently, such as regression or compatibility testing? If so, it’s a prime candidate for your first GenRocket project. By automating this test data case, you’ll save countless hours each time the test is run. Your test data case will automatically be saved in the GenRocket G-Repository for future use. Each time you need to test data, just run the test data case again, by executing a command to generate fresh, accurate synthetic data, on demand, directly into your CI/CD pipeline. By designing a test data case once for frequently used test procedures, you’ll be able to re-use the test data case over and over and maximize your time savings and compound the efficiency benefits.
5. Data with well-defined data models (schema file, DDL or JSON metadata)
Another excellent starting point is to use a well-known and pre-existing data model to produce fresh synthetic test data. A variety of data model formats (e.g., Database schema file, DDL, or JSON metadata) can be imported into GenRocket and used to rapidly create new synthetic test data. The platform uses intelligent automation to extract the metadata and assign appropriate data generators from the GenRocket Data Warehouse. Intelligent wizards help you to validate the data relationships and configure test data case parameters, then the system is ready to produce the volume and variety of synthetic data needed for testing. GenRocket will automatically replenish their test data with freshly created synthetic data at runtime so testers aren’t dipping into the same ‘data well’ but are instead using a fresh copy of data for each test run. GenRocket’s intelligent automation makes it easy to incorporate existing data models into its platform accurately and quickly.
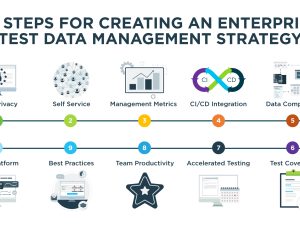
DevOps teams are often pressured to save time on testing, or to condition their data with the variety needed for a specific type of test. By using GenRocket’s intelligent automation for projects that have the longest provisioning time, limited test coverage, largest data volume, highest frequency of testing, or well-defined data model, you can save a tremendous amount of time and effort while producing the volume and variety of test data needed for thorough testing.