The Power of Augmenting Production Data with Synthetic Data
Obtaining test data for functional testing usually involves copying and subsetting the production data values used by the software under test. Production data must be carefully masked to comply with data privacy regulations and is often provisioned for testers by a dedicated test data support team. The assumption behind this approach is that production data is realistic, readily available, and made secure for testing.
According to the 2021-2022 World Quality Report, over half of QA teams work with copies of production data for testing with a similar percentage of respondents who follow the test data practices outlined in the graphic below. Collectively, these survey results represent the status quo for test data management across multiple global industries.
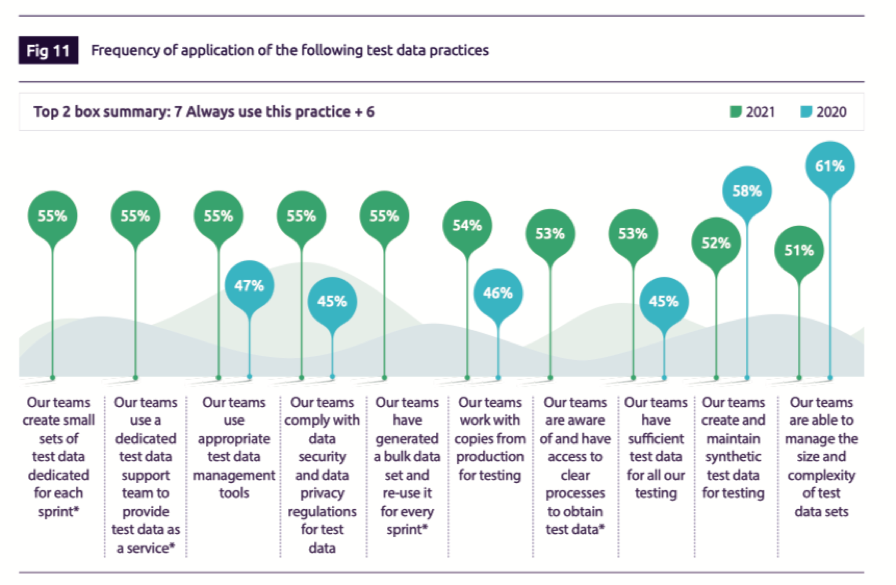
It’s interesting to note the last two data points in the graphic. The number of organizations who create and maintain synthetic data for testing declined by 6% and the number who felt they were able to manage the size and complexity of test data fell by 10% during the last year.
These results suggest a rush by QA organizations to use synthetic data in 2020 only to find that it was too difficult to implement or failed to meet their testing requirements. We believe that in response to GDPR and other privacy laws, QA organizations rushed to deploy one of the many synthetic data solutions that scan and replicate a production database with synthetic data that is, by its nature, secure. Inevitably, these organizations found that a database replica offers no additional benefit over production data that has been properly subsetted and masked. And the complexity of owning and operating an additional platform without additional benefits was not an attractive option.
Synthetic Data Augmentation – A Synergistic Approach
GenRocket’s approach to synthetic test data generation is both different and unique. Instead of replicating a production database, GenRocket can be used to augment a production database. This replaces the either/or approach of replacing real data with synthetic data. Synthetic data augmentation provides the synergy of combining production data with synthetic data. This allows the tester to conquer a major testing challenge – how to achieve full coverage in functional testing.
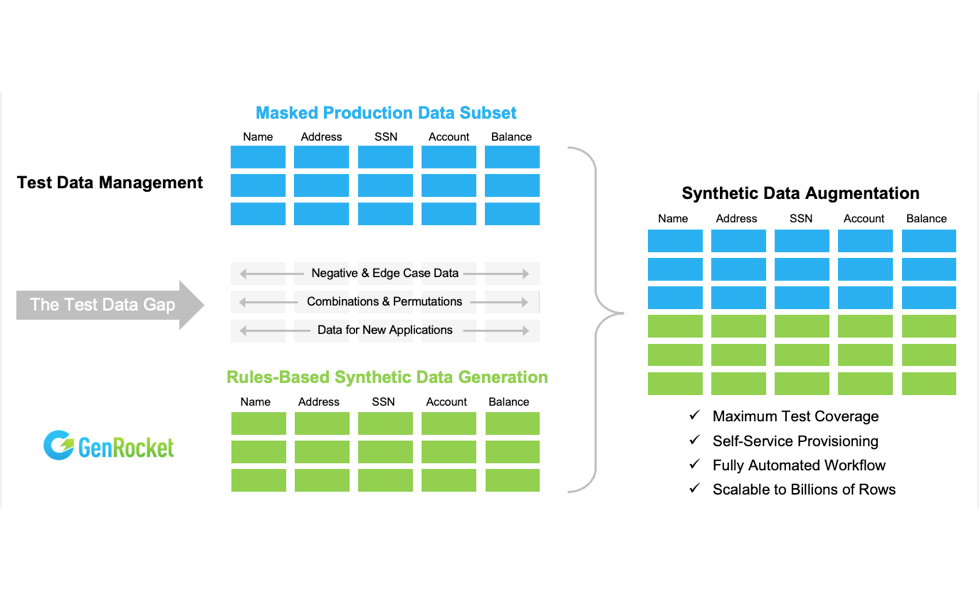
Consider the diagram below. Test data sourced from production is real, accurate data that has been masked and delivered to a test environment. This test data will contain production data that matches test case requirements as well as production data that does not match test case requirements and this results in a test data gap.
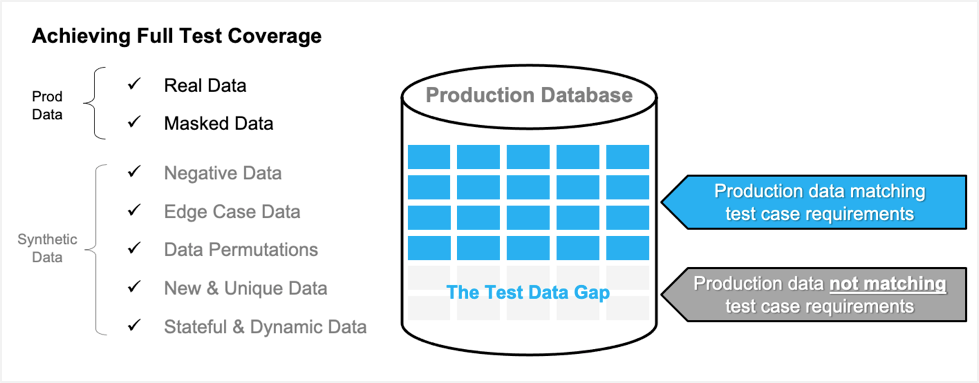
By itself, production data does not allow for negative testing, edge case testing, full combinatorial testing, and for greenfield applications where there is no historical data of any kind available for testing. Additionally, finding dynamic data for testing stateful transaction workflows can be extremely problematic with production data. Fortunately, all of these conditions can be satisfied by generating synthetic data to use in combination with production data. This creates a win-win strategy for using synthetic data to maximize coverage in all forms of testing.
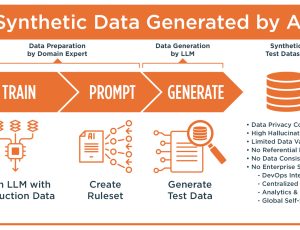
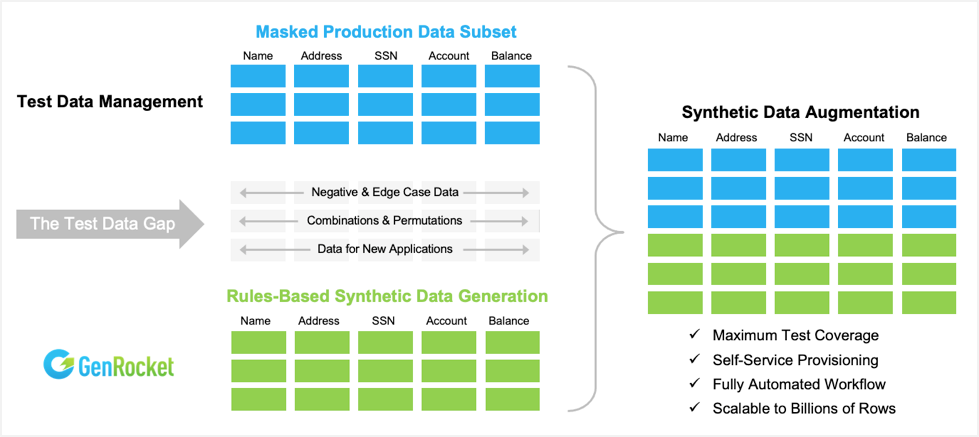
The diagram below illustrates the concept. Test data management systems are used to provision test data by copying, masking and subsetting production data for a given test case. Then testers configure the GenRocket platform to generate synthetic data based on a set of rules that define negative and edge case scenarios, combinations and permutations, and data for new applications.
Synthetic data augments production data to maximize coverage. And the use of GenRocket’s self-service platform eliminates the complexity of operating parallel systems for production and synthetic data. With GenRocket, synthetic data is generated on-demand during automated test execution This eliminates the need to store, refresh or reserve test data for future test runs. And it allows testers to deploy and operate a fully automated workflow for continuous testing that is scalable to billions of rows.
The use cases for synthetic data augmentation are limitless and the strategy can be applied to any form of functional or non-functional testing. To date, GenRocket has not encountered a data type that cannot be generated or an output data format that cannot be reproduced, whether it’s structured or unstructured data.
If your organization is working to maximize coverage and accelerate testing, synthetic data augmentation can help to achieve both goals simultaneously. It’s a way to introduce synthetic data into your testing regimen in a way that delivers value without adding complexity. If you would like to see the GenRocket solution in action, schedule a live demonstration and one of our test data automation experts will show you a synthetic data solution to meet your toughest testing challenge.