Adopting a New Synthetic Data Paradigm for Software Testing
The traditional paradigm for provisioning data for software testing is evolving. What the industry currently refers to as Test Data Management (TDM) is changing with the times. Everything associated with the software release pipeline is being automated and integrated, except, that is, for the traditional and monolithic TDM model. With the help of synthetic data and Test Data Automation (TDA), software development and testing teams can unlock new levels of quality and efficiency.
New synthetic data startups have hitched their wagon to the rising star that is AI and ML. They are profiling and generating synthetic replicas of production databases to train machine learning models while eliminating the use of sensitive (PII/PHI) data in dev and test environments. Recent market data published by Allied Market Research tells us the synthetic data market will grow at 35% per year and reach 3.5 billion by 2031.
But these new startups fall short when it comes to what today’s quality engineering teams want and need. At best, most of the new synthetic data startups represent a new spin on the same old TDM story. Generating a synthetic copy of production data doesn’t eliminate the shortcomings of testing with masked production test data, it only perpetuates them.
The Limitations of Traditional and Synthetic TDM
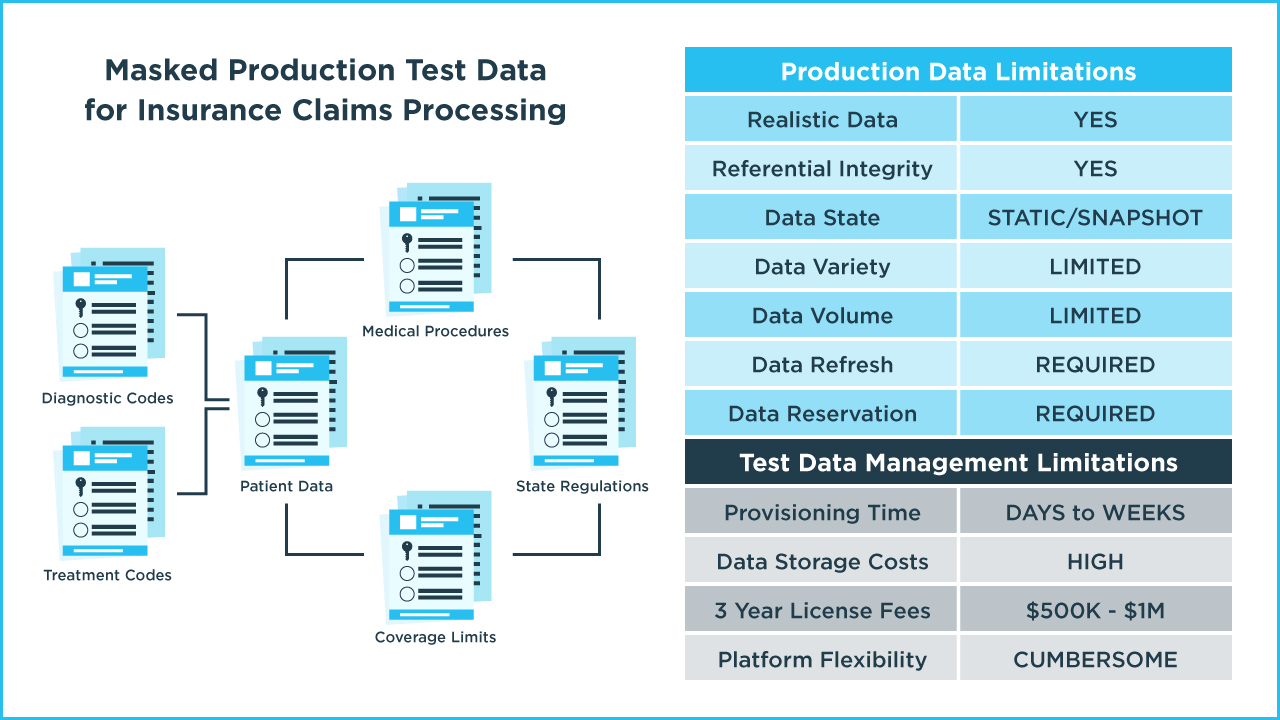
Both production data, as well as a synthetic data replica of a production database, provide a secure copy of production data with referential integrity. However, production data (copied or synthesized) is best used to analyze and understand the behavior of your data rather than as providing test data for quality engineering.
What are the drawbacks of using production data as test data?
- Lacks accuracy & validity when data is used in shared test environments
- Lacks the necessary volume of data
- Lacks unique, negative and edge case data
- Lacks all permutations & combinations
- Lacks data matching specific rules & conditions
- Is difficult to integrate directly into test cases in CI/CD pipelines
Typically, the data variety that dev and test teams can obtain from production data covers about 20% to 30% of the potential input values that are needed to fully test the software. And to test specific edge case conditions or negative testing scenarios, test data has to be created manually, through spreadsheets or by writing scripts.
In addition, because production data is static, it does not dynamically adapt during test execution. For example, to determine if an insurance claim should be paid, the current balance of the subscriber’s deductible must be accurately checked so a decision to make a full payment to the provider can be validated. To do this properly, test data must be dynamic and stateful throughout the simulated transaction flow.
For more comprehensive testing, a full set of combinations and permutations of data values is needed but is rarely present in a production data subset. Additionally, the volume of data available for performance testing may not match peak load conditions in the real world.
Finally, if production data (or a synthetic data copy) is in a shared database during a test run, the data can be changed by a test. This means test data becomes unpredictable, and if used by another dev and test team, test results may be inaccurate. As a result, production data must be reserved by each team in advance and refreshed prior to subsequent testing. Sometimes this data refresh practice is done frequently, most often it’s not, which can lead to “polluted” test data and test reliability issues.
The traditional TDM approach is fast becoming outdated. Beyond the data quality gaps previously mentioned, data provisioning cycles can take days or even weeks and data refresh cycles are usually even longer. Storage costs for copied and masked test data can be hundreds of thousands of dollars. And license fees for traditional TDM platforms can exceed $1 million dollars. Lastly, TDM platforms can be complex and cumbersome to set up and manage.
Evolving from TDM to Test Data Automation (TDA)
The 2022-2023 World Quality Report recommends that organizations take advantage of the increasing automation of data provisioning and the growth in synthetic data generation. Moreover, they recommend the implementation of a global test data provisioning strategy.
The survey found that 31% of organizations have defined an enterprise-wide test data provisioning strategy but are having difficulties implementing it efficiently. Only 20% of the respondents said they have a fully implemented, enterprise-wide test data provisioning strategy.
A second key take-away from the report is that organizations need to look at automated test data provisioning as an integral part of the continuous integration and delivery pipelines.
In 49% of organizations, the process of provisioning test data is automated, but this automation is independent of the overall CI/CD pipeline automation. For 42% of organizations, the manual provisioning of test data remains one of the top barriers to integrating the provision of test data into the CI/CD pipelines.
Here’s how Gartner defines synthetic data:
Synthetic data is generated by applying a sampling technique to real-world data or by creating simulation scenarios where models and processes interact to create completely new data not directly taken from the real world.
Gartner’s second definition of synthetic data (in bold) represents GenRocket’s synthetic data vision and its technology platform. We believe in the on-demand and automated delivery of synthetic test data that is tightly integrated into the release pipeline, if not the entire DevOps ecosystem. For GenRocket, synthetic data is not a copy of production data, it’s a controlled synthetic representation of what a production data environment should look like in order to meet the specific needs of any category of testing.
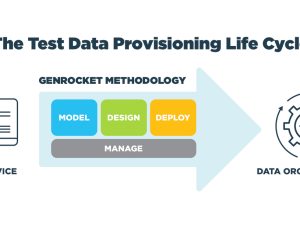
In GenRocket’s approach to synthetic data and Test Data Automation, a data model combined with a well-defined set of rules for data generation are all you need. Just import a database schema or the metadata that defines the target data model, define the test data requirements, and configure the volume, variety, and output format of the data that is needed for testing. Millions, even billions, of rows of data are not a problem. And to generate synthetic data in real-time, simply embed a small instruction set into your test case and run it.
GenRocket’s self-service platform delivers synthetic data on-demand that is controlled and conditioned for each test. Data generation is performed as automated tests are executing in any structured, semi-structured, or unstructured format and a fresh set of data is generated for each test run. GenRocket provides fully automated test data delivery.
Now let’s look at the ways synthetic data and TDA can remove the limits imposed by production data and traditional TDM.
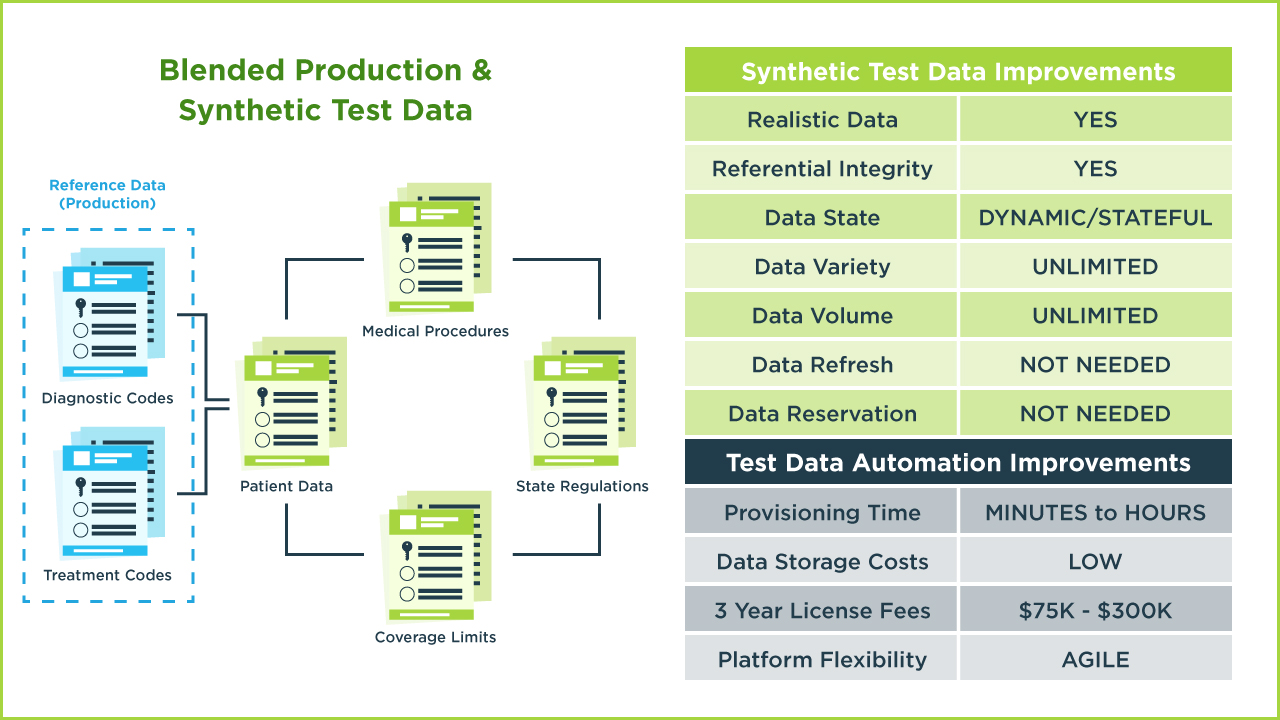
While synthetic data can be used to simulate any data environment, there are still times when you’ll need real production data values. During transaction flows, there are often key fields that serve as reference data to provide relational connections between multiple data entities. GenRocket allows for blending production data with synthetic data with complete control of which data entities and data elements are to be retrieved from production and which ones are to be synthetically generated during the test.
Another benefit of synthetic data generated by GenRocket is the ability to test with data that is both dynamic and stateful. For example, synthetic data can be generated for one segment of the test case with different values or varieties of data generated for other segments of the test case that are conditional on transaction flow and calculated results. This allows for business rules and program logic to be fully and accurately tested.
There are no limits on the variety and volume of data that can be generated by the system. With over 700 data generators and 100 output formats supported, there is literally no data environment that can’t be simulated with controlled and conditioned synthetic data. And because the data is generated and re-generated for each test run, it’s always a fresh copy that never requires data reservation.
Test Data Automation represents a quantum leap forward from the practice of Test Data Management. Data provisioning time can be reduced to minutes or hours, depending on the volume of data being generated. Storage costs are minimal. License fees are a fraction of the cost of legacy TDM platforms. And the entire synthetic data generation process is much more flexible, adaptable, and agile.
Best of all, TDA can be an evolutionary path. It allows dev and test teams to shift left and start small with synthetic data generated for unit and component testing. Gradually, small Test Data Cases can be combined into larger Stories and Epics and repurposed for more complex integration and system testing. And all Test Data Cases can be easily modified for full regression and performance testing at each stage.
If you’re organization is considering an evolution from TDM to TDA, we can help. Our synthetic data experts have developed a full technology deployment and adoption program that any global enterprise can implement, one step at a time. If you’d like to get started, just click the link below to schedule a live demonstration of the platform.