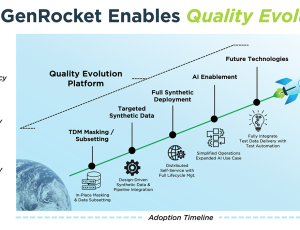
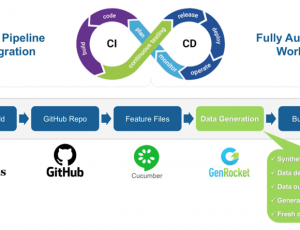
How Synthetic Data Impacts the Future of Test Data Management
Part 4: Positioning GenAI in the Landscape of Synthetic Data Solutions
This is the fourth article in a series devoted to ways GenAI tools can be leveraged for synthetic data generation. In the first three articles, we explored three key aspects of incorporating GenAI into an enterprise-class synthetic data generation solution:
- “Leveraging GenAI to Deliver Enterprise-Class Synthetic Data” examined the impact of Generative AI on data quality in complex environments, introducing GenRocket’s Synthetic Test Data Automation platform as a superior solution for enterprise-scale deployments.
- “Provisioning Synthetic Data with GenAI at Enterprise Scale” focused on scalability requirements for global data provisioning, showcasing GenRocket’s enterprise-class features and the potential of seamlessly integrating GenAI with GenRocket.
- “Synthetic Data Generation of Complex Documents with GenAI” presented a real-world case study, demonstrating how a prominent legal firm leveraged GenRocket’s platform integrated with GenAI to generate diverse, realistic datasets for AI-assisted applications.
In this fourth and final installment we will step back and compare the main alternatives for provisioning test data in a quality engineering (QE) environment. The evolution of software development has necessitated advanced methods for managing and generating test data. Traditional Test Data Management (TDM) has been the cornerstone of test data provisioning, but newer technologies like Synthetic TDM, Generative AI (GenAI), and Synthetic Test Data Automation (TDA) have emerged, offering a variety of improvements in efficiency, scalability, and security. This article explores these four categories, highlighting their different approaches and capabilities.
Traditional Test Data Management
In traditional TDM, test data is copied from a production environment, subsetted into a manageable volume of data for testing, and sensitive data (e.g. PII) is masked to obfuscate protected and private information. This “copy/subset/mask” paradigm requires expensive test data storage, and production data is restricted to “happy path” data. Therefore, all of the data gaps (new data, negative data, different data rules and permutations) have to be created via manual methods (usually via spreadsheet). In addition, test data quickly gets “stale” when it is modified during test procedures or when there are any changes to the data model / schema which requires a “data refresh”.
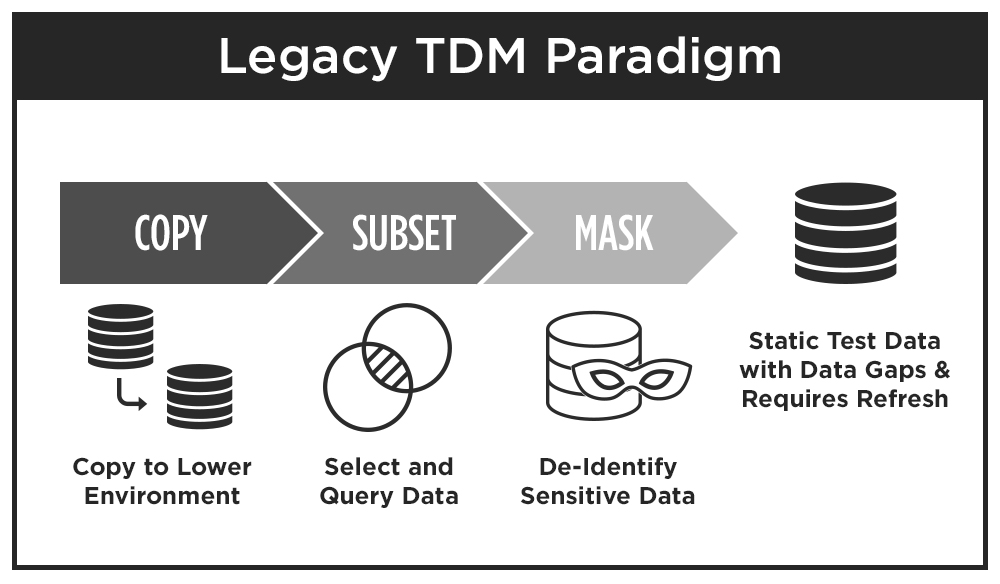
As a result, traditional TDM can require long provisioning cycles as internal data security / compliance teams review masked data sets to ensure no PII slips through the masking process – an inherent risk of the traditional TDM approach. And data delivery cycles are lengthy because masked subsets of data sit in a database and the test data isn’t mapped into the test cases – another step that takes time for testers & developers to get the exact volume and variety of data they need for each test case.
Synthetic Test Data Management
Synthetic TDM represents a variation on the traditional TDM theme. This category is based on a new class of synthetic data technologies that can be used to provide secure synthetic data for shared data analysis, training data for machine learning, and also to provision test data for use in QE environments.
Synthetic TDM uses advanced data profiling techniques to scan a production data source and create an exact statistical replica of production data using synthetic data. This approach improves on the data security concerns of traditional TDM but has the same expensive test data storage requirements of traditional TDM. And because production data (in this case, a synthetic replica) is still just “happy path” data, all of the data gaps (new data, negative data, different data rules and permutations) still have to be created via manual methods.
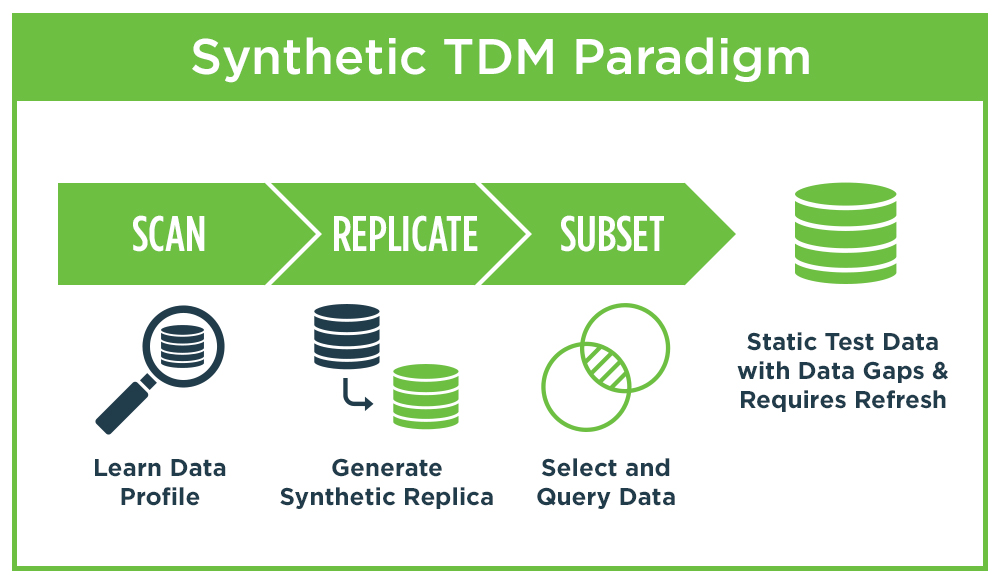
The principal benefit of this approach Is the ability to replicate production data with a secure synthetic copy. This is valuable for data analysis and machine learning applications, but less valuable for software testing where volume, variety and different formats are required. Like traditional TDM, there are many data gaps in synthetic copies of production data. All the test data for full test case coverage still has to be created manually.
And because synthetic database copies sit in a database, the test data isn’t mapped into the test cases – another step that takes time for testers & developers to get the exact volume and variety of data they need for their testing.
Generative AI
The third category of test data provisioning is synthetic data produced by Generative AI. GenAI is being intensely studied as a way to quickly generate synthetic data through the use of predesigned “prompts” that dictate the data requirements combined with a sizeable data sample for training a large language model (LLM) to replicate the characteristics and statistical properties of the data. As discussed in Parts 1 and 2 of this series on using GenAI for provisioning synthetic data, there are two major drawbacks to this application of the technology.
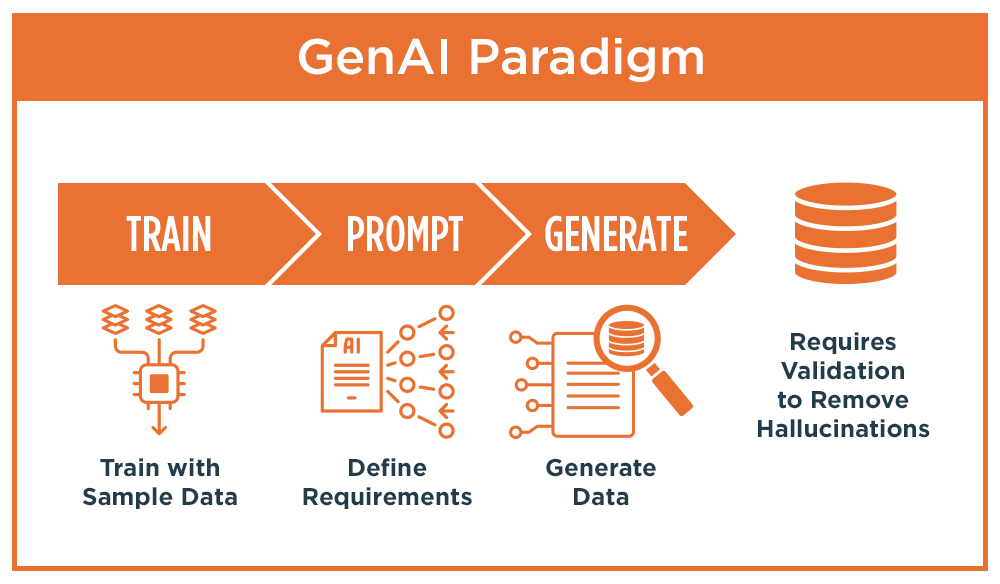
The first drawback of GenAI is the lack of certainty around data quality. GenAI is notorious for generating “hallucinations”, generated data that may not be completely accurate or factual. Hallucinations can be caused by a number of factors, but the most obvious one is publicly available LLM’s are not trained on internal enterprise information. And even when internal training data is provided, a prominent study found the accuracy is only 54% when prompted to reproduce data simulating an enterprise SQL database. Due to the lack of transparency in GenAI, it’s impossible to know how, where, and why those data quality issues occurred.
An additional data quality risk is lack of referential integrity when generating data tables with parent/child/sibling relationships. And like the other data provisioning methods described above, GenAI can suffer from data gaps that require manual data augmentation. Finally, the use of GenAI carries the risk that sensitive production data used to train the model can be compromised in a lower environment, and If copyright protected data is used for training the model, the organization could be at risk for copyright infringement.
The second major drawback of GenAI is its lack of enterprise scalability. To scale synthetic data generation across a global QE environment, full lifecycle management of the data provisioning process is needed. That starts with a distributed self-service portal to provide developers and testers with an easy way to requisition and receive their data. It continues with an ability of the platform to deliver the precise volume, variety and format of data needed for each category of testing. The cycle is complete when the required data is orchestrated into a testing framework in the CI/CD release pipeline.
GenAI simply does not provide lifecycle management of the data provisioning process. It can provide a solution for simple use cases of structured/tabular data or for generating large and highly controlled volumes of textual and conversational data for training chatbots and virtual assistants. But for the complex, highly integrated data landscapes used by today’s enterprise systems, it falls short.
Synthetic Test Data Automation
The fourth category for provisioning test data is synthetic Test Data Automation, or synthetic TDA. This is the approach used by GenRocket. It is based on modeling a data source by examining its metadata (e.g., a database schema file or supplied data definition language), and assigning intelligent data generators to produce a synthetic dataset that matches that data model. The intelligence of the data generators allows for the application of rules and conditions that allow precise control over the volume, variety, and format of data that is generated. This process is called “design-driven data” and allows a test data engineer to create an executable instruction set that can be added to any test case to generate synthetic data in real-time during automated test operations.
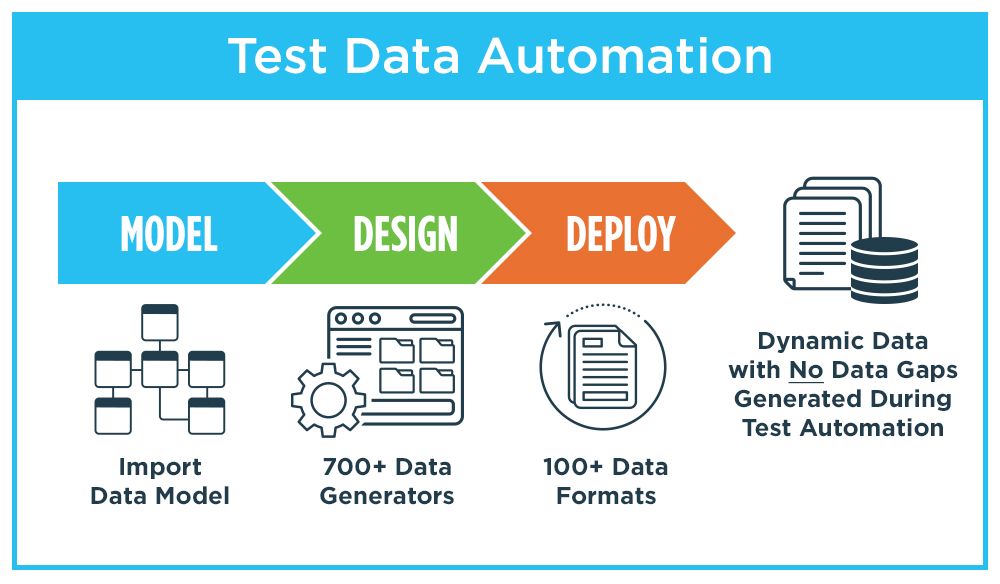
The process flow for synthetic TDA Is characterized by three steps: modeling the data structure, designing the data generation requirements, and deploying an executable test data case into a test automation framework. This model/design/deploy process replaces the more cumbersome process of copy/subset/mask found in traditional TDM. Because the data generation process follows a design that is mapped to the requirements of each test case, there are no data gaps. And because the data is only generated during the testing process there is no requirement to store the data for reuse. That’s because a fresh copy is generated for each test run.
With synthetic TDA, data generation can be orchestrated to deliver synthetic data to simulate complex environments that may include structured, unstructured, event or message driven data and generate the required data at the precise moment the data is needed. This allows for accurately testing complex workflows that travers multiple systems in an integrated fashion. And like the other synthetic data generation solutions, synthetic TDA produces totally secure data that is 100% compliant with all global privacy laws.
As described in part three of this series, GenRocket has innovated a way to leverage GenAI as part of its synthetic test data automation platform. Combining the conversational and textual benefits of synthetic data generated by Gen AI with the more controlled and tabular data values generated by GenRocket, developers and testers can have the best of both worlds. Additionally, the GenRocket platform brings the scalability and flexibility of a self-service platform to organizations that need to provision synthetic data on a global scale.
And to facilitate the transition from the use of production data to the use of generated synthetic data, GenRocket has incorporated traditional TDM capabilities into its platform. This allows dev and test teams to follow a familiar process as they adopt and deploy newer synthetic data technology. GenRocket provides organizations with a single data provisioning platform to enable a graceful migration from traditional TDM to the more flexible, agile, and automated use of synthetic test data automation.
Here is a detailed comparison to learn more about comparing Synthetic TDA with Traditional and Synthetic TDM. And if you’d like to learn more about how synthetic TDA can be introduced into your quality engineering environment, schedule a personalized demo with a GenRocket expert and be sure to bring your most difficult test data challenges.