How to Ensure Data Validity When Testing with Synthetic Data
Data validity is essential when testing the accuracy of business logic designed into information systems that process complex transactions. Without guaranteed data validity, software testing succumbs to that age-old dilemma – garbage in, garbage out – and puts software quality at risk.
Increasingly, dev and test teams are turning to synthetic data to accelerate test cycles and maximize coverage with expanded data variety. However, synthetic data generation is still a new and different approach when compared to masked production data, and so questions about the validity of synthetic data have emerged.
Does generating synthetic data compromise the validity of test data when compared with real data copied from a production database?
The simple answer is no. Since GenRocket allows the generation of pattern data, permutation data, data by percentage, data with specific dates in the past, present, and future, data by rules, conditions, calculations, and many more options, GenRocket’s Test Data Automation platform provides better data validity than production data and with infinitely greater data variety, volume, and velocity. In essence, GenRocket provides the data needed to fully test the business logic of a complex transaction flow.
Here’s how it works. Data validity is achieved by blending generated synthetic data with important production data values we’ll call Reference Data. In most transaction flows, there are key fields that define the relationships between multiple data domains and serve as reference data for connecting the dots between various data elements. For example, an ecommerce application brings together product, vendor, customer, and payment domains when a customer makes shopping cart purchase from one or more vendors with a desired method of payment.
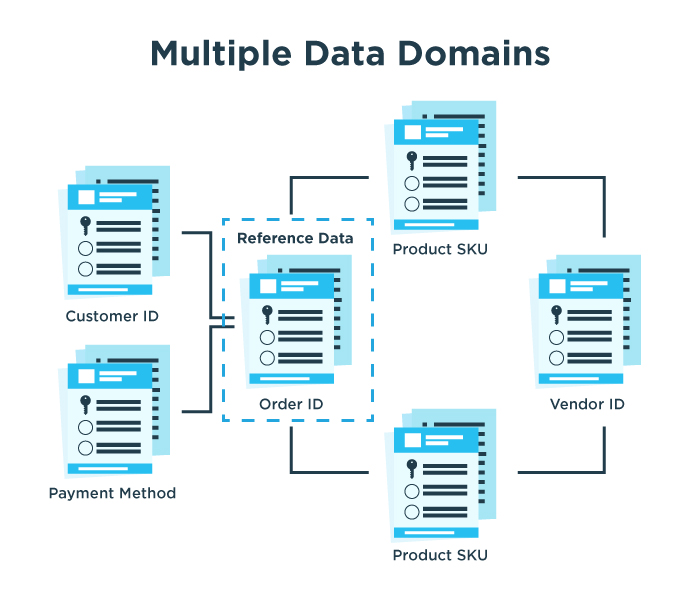
For each transaction, an order number serves as reference data that links to key fields in the customer, vendor, product, and payment domains that are included in the order. Similarly, the customer ID is reference data that links to their purchase history and stored methods of payment. And the vendor ID is reference data that links to product SKUs offered by that vendor in the online store.
GenRocket has the ability to query reference data values from a production database and blend them with controlled and conditioned synthetic data to provide the best of both worlds – data validity and unlimited data variety. Reference data retrieved from production ensures the validity of data relationships in a multi-domain a transaction flow. At the same time, controlled and conditioned synthetic data can be generated to replace sensitive (PII/PHI) data and extend the volume and variety of test data far beyond what is available in a production database.
Here’s an example of Reference Data in the healthcare industry. When processing insurance claims, an ICD-10 code is used to represent a medical diagnosis while a CPT code is used to represent a corresponding medical treatment or procedure. The standardized library of ICD-10 and CPT codes used for claims processing are examples of reference data because they’re used as the basis for determining the insurance coverage provided to the patient and the payment amount that is made to healthcare providers.
During program execution, reference data is used to process information, make decisions, and calculate results. Medical codes are used to make billing and payment decisions. Health Plan Identifier (HPID) codes are used to identify the level of coverage for various treatments. And the member ID determines specific benefits for a given patient. When testing transaction flows, reference data is essential for testing conditional logic and control flows in the software under test.
When processing insurance claims transactions, it’s important to ensure the proper ICD-10 codes have been used for a given illness or injury and the proper CPT codes have been used for medical services provided. That’s because improper and inaccurate coding is a common source of invalid and rejected claims and/or overpayments that represent lost revenue for the carrier.
Valid ICD-10 and CPT codes are cross-checked with coverage limits based on the patient’s eligibility and healthcare plan. The reference data used for testing this business logic would also include the plan identifier and the member ID.
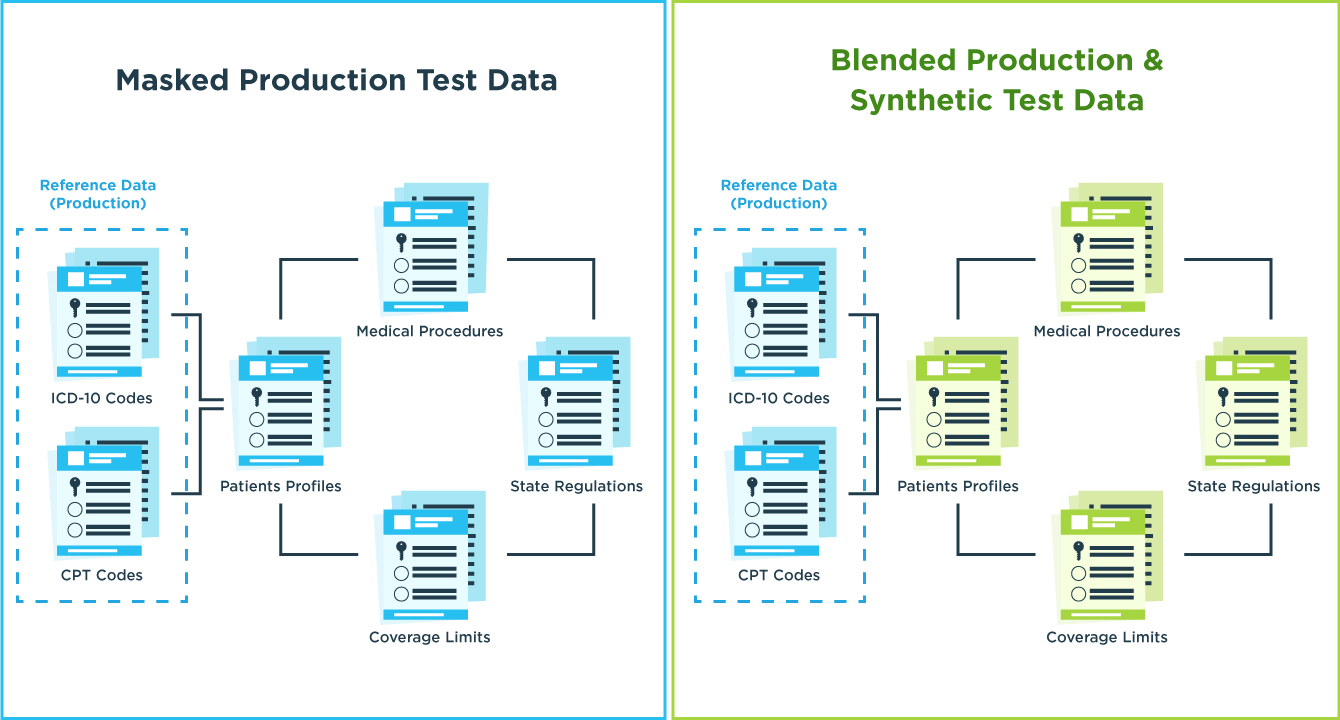
The relationships between medical codes, policy provisions and patient eligibility all rely on the validity of reference data. To ensure data validity, GenRocket imports the data model defining these relationships, queries the real production data values, and combines them with synthetic transaction data to maximize test coverage. This allows for testing positive and negative use cases, edge case scenarios, and all combinations and permutations of transaction data values.
By itself, production data doesn’t provide the data variety that is needed for testing transaction flows with full coverage. Additionally, sensitive data (PII/PHI) values found in production data must be profiled and masked prior to use in a lower test environment. This can take days and weeks to provision. And for new policy provisions, production data may not even exist, forcing the team to manually create the data varieties they need.
Synthetic data removes these limitations. GenRocket can retrieve reference data from an existing production database and blend it with synthetic test data that is 100% private and secure. Then synthetic data can be generated in the volume, variety, and format required for any category of test.
Examples of Enumerated Reference Data
Reference Data that already exists in the production database and used to define relationships between data tables is also known as enumerated data. The medical codes in the claims processing example above are good examples. Here are some other examples of reference data that is also enumerated data.
- Banking – account numbers, customer numbers
- Insurance – member numbers, policy numbers
- Government – VIN numbers for automobiles, account numbers for taxation
GenRocket’s unique Query Generators enable developers and testers to retrieve any enumerated reference data from a production database for testing. These real production data values are then blended with synthetic data to enable a fully secure and comprehensive test run.
Dynamic Reference Data – An Insurance Policy Example
Reference Data can also be generated dynamically by an application during a transaction processing workflow. In this case, the purpose of reference data is to provide data validity and consistency across the entire end-to-end transaction. Let’s look at the workflow for issuing a new insurance policy to see the use of dynamic reference data in action.
Here is the basic workflow:
- A new customer needs an insurance policy
- An agent requests a quote to be generated
- A quote with a premium is sent to the agent
- Agent shares the quote with the customer
- A payment is made, and the policy is bound
- The insurance policy issued to the customer
The dev and test teams are ready to test this workflow in the policy management system. The following data elements have been identified as Dynamic Reference Data:
- Customer ID
- Agent ID
- Quote ID
- Payment ID
For the purpose of this test, it’s not necessary to retrieve these data elements from a production database. They are not Enumerated Values. They are Dynamic Reference Data values created for each new policy as they are generated. New policies issued by the system must be tested with valid reference data having specific data relationships.
- The Customer ID is related to the quote being generated
- The Agent ID is related to the quote and the customer
- The Quote ID is related to the agent and the customer
- The Payment ID is related to the quote, agent, and customer
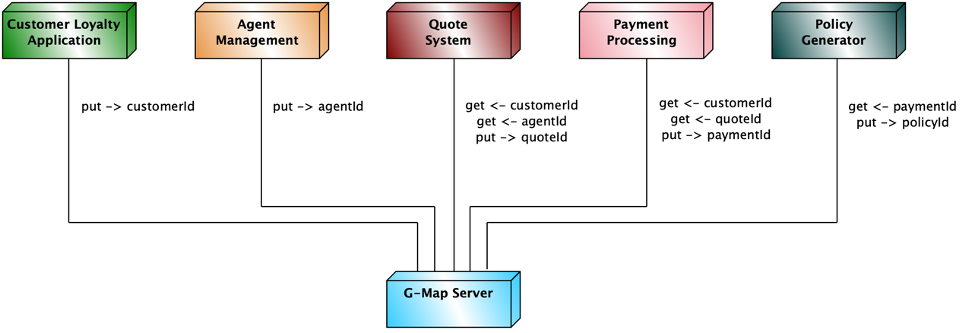
In GenRocket, a Test Data Case is created containing Scenarios for generating each reference data value and stores it in a mapping table that is referenced during the workflow. Reference data is retrieved by the Scenarios and combined with controlled synthetic data variations of policy data dynamically during test execution.
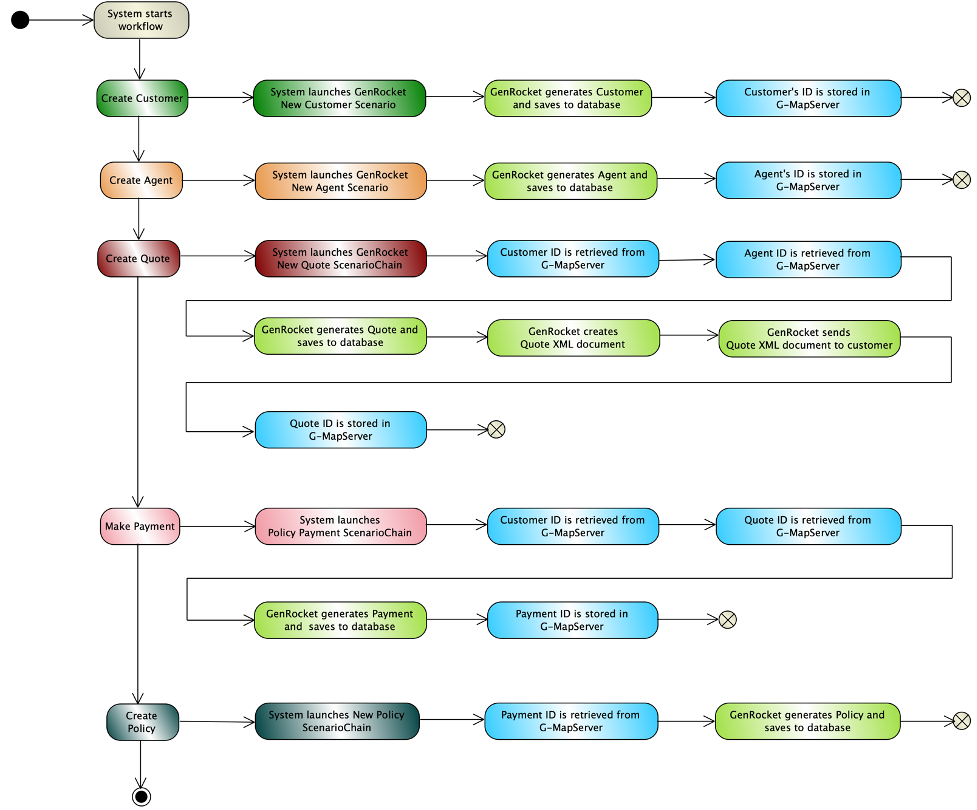
GenRocket enables the validation of business logic in complex workflows with related data elements that are unique to each policy. The combination of controlled and conditioned synthetic data allows for testing all possible data variations to maximize test coverage.
Here is a high-level summary of the GenRocket solution for ensuring data validity when generating synthetic data for complex transaction workflows.
- Retrieve Enumerated Reference Data Values
Import the data model and assign query generators to retrieve Enumerated Reference Data - Map to Sensitive Data Values
Use the data model to map sensitive values and replace with a synthetic data equivalent - Test with Dynamic Reference Data Values
Use a Mapping Table to store/retrieve Dynamic Reference Data during complex workflows - Augment Test Data with Controlled Data Variations
Merge queried data with the volume/variety of synthetic data needed to maximize coverage
If you’d like to see a live demonstration of these powerful Test Data Automation capabilities in action, click on the link below to schedule a session with one of our synthetic data experts.