How to Leverage Metadata for Synthetic Data Generation
Enterprise Metadata Management is technology used to centrally manage and deliver high quality data and trusted information for business analysis and decision-making. Metadata is often referred to as “data about data” and describes the content, governance, and structure of enterprise information. Metadata is often used to create data catalogs that aggregate, group, and sort multiple data sources to make them accessible for a wide variety of use cases.
Data Catalogs use metadata to provide a “single source of truth”, a reference point for maintaining data quality and consistency in a continuously changing data environment. Leading metadata management platforms, such as Abinitio and Alation, manage the dynamic nature of enterprise data with the use of machine learning to learn and adapt to changes in the data environment.
A Perfect Data Model for Synthetic Data Generation
Metadata provides a perfect data model for generating synthetic test data. That’s because metadata operates as a continuously updated template of the data structures and data relationships used by data sources across the enterprise.

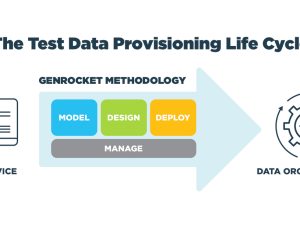
This is the same approach used by GenRocket to ingest a SQL database schema, XML Schema Definition (XSD) file, or DDL file to define a synthetic data model. Each one offers a different method for replicating the structure of target data environment as the first stage of GenRocket’s Model/Design/Deploy/Manage Test Data Automation Lifecycle. GenRocket provides many ways to import or create a data model into its Synthetic Test Data Automation platform as illustrated below.

Modeling Data with JSON Schema Files
A JSON Schema is a standard format that defines what data is required by an application and how to handle that data. GenRocket allows software developers and test engineers to import JSON Schema files created by metadata management platforms like Abinitio and Alation to generate synthetic data based on those data definitions.
Because there are so many ways to describe data models using JSON, it is not practical for GenRocket to implement code for each of them. So, using JSON’s Schema Definition Language, GenRocket has defined a JSON Data Definition Language (DDL) as a standard for customers to funnel their JSON formats into GenRocket’s JSON Schema.
GenRocket’s JSON DDL Schema is clean, simple, and contains only the necessary elements to quickly define table definitions to include:
- table names
- column names
- dataTypes
- maxLength
- nullability
- required
- metadata
- hints
- observable characters
- maxCharLength
- minCharLength
- maxValue
- minValue
- primary keys
- foreign keys
GenRocket’s DDL JSON Schema enables importing the many different and ever-growing JSON formats into its platform and successfully turning those formats into the components used for synthetic data generation: Domains with Attributes and Generators with Parent/Child Relationships. The image below provides a grid view of GenRocket’s DDL JSON Schema.
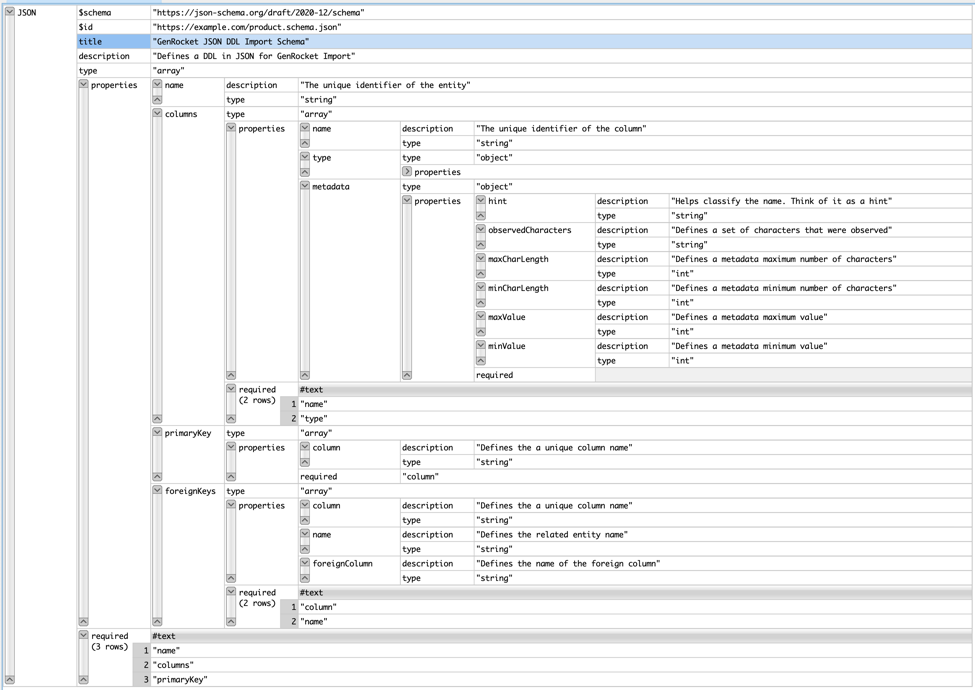
Once imported into the GenRocket platform, metadata is used to build out a test data project – a template for data generation. Data relationships are quickly established with a domain referencing wizard and data generators are automatically assigned to domain attributes by an intelligent data warehouse.
Increased Acceleration and Improved Coverage
By leveraging the metadata used to catalog enterprise information, DevOps teams can greatly accelerate test cycle time. Now complex data structures used by enterprise applications can be quickly imported and used to generate real-time synthetic test data for any test case. This eliminates the “request and wait” process of provisioning test data from a production database. Instead, GenRocket delivers secure, fresh, accurate, and controlled synthetic data generated on-demand with a self-service platform.
In addition to test cycle acceleration, this approach also enables DevOps teams to increase test coverage by generating more comprehensive test datasets that include positive and negative data values, edge cases, data patterns, combinations, and permutations. Synthetic data can be configured to follow business rules and blended with enumerated data values to test and validate complex workflows across multiple integrated systems.
As organizations increase the visibility, accuracy, and consistency of enterprise information with metadata management systems, DevOps teams can now leverage metadata to build ready-to-run templates for real-time synthetic test data. The integration of Test Data Automation with Enterprise Metadata Management can lead to dramatic improvements in the speed and quality of automated testing as organizations scale the use of synthetic data for all aspects of software quality assurance.
If your organization has deployed a metadata management platform, contact GenRocket to learn how your data environment can be quickly and accurately modeled for synthetic data generation. Just schedule a live demo of our platform and bring your toughest test data challenge. The more complex the data environment, the greater the impact of GenRocket’s synthetic data platform on quality and speed.