Leveraging GenAI to Deliver Enterprise-Class Synthetic Data
Part 1: The Impact of GenAI on Data Quality in Complex Data Environments
Overview: GenAI Enterprise Adoption and Risk Factors
According to a recent study by PagerDuty, 98% of fortune 1000 companies are experimenting with GenAI. At the same time, most are taking a cautious approach as they establish appropriate use cases, guidelines, and quality standards to govern its deployment. There are many risks associated with GenAI and they are giving many executive leaders cause for concern.
According to Broadridge Financial Solutions, a global fintech leader providing technology-driven solutions in investor communications, securities processing, and data analytics, only 44% of financial services firms are making a moderate to large investment in GenAI, with only 4% making a very large investment. And despite its promise, only 46% of firms that are actively using GenAI have a clear strategy in place to mitigate its risks.
Here’s a recap of the most often cited risk factors for GenAI:
- Information Accuracy: GenAI AI tools (e.g., ChatGPT, et al.) are notorious for hallucinations, incorrect information produced by a generative AI model but presented as true and accurate.
- Data Privacy: If a data sample used to train a GenAI model contains sensitive patient or customer information, there’s a risk that confidentiality will be compromised and/or privacy laws violated.
- Copyright Infringement: If copyright protected data is used to train a generative AI model, or if the output generated by the model closely resembles protected data, the organization could be at risk for copyright infringement.
- Model Transparency: GenAI tools operate like a black box. Users see the inputs and the outputs but have little or no knowledge of what’s happening in between. This undermines the ability to monitor, document, and manage compliance and continuous improvement.
Evaluating GenAI for Enterprise Scalability
An emerging use case for GenAI is the generation of synthetic test data. While GenAI is very good for generating some categories of data, it’s very limited for others. One area where the technology is very strong is generating content that is conversational or textual in nature, such as marketing copy for articles and web pages or chatbot conversations for customer service and support.
However, when it comes to generating tabular synthetic test data to simulate the data used for extensive application testing, there are too many limitations. GenAI can easily generate basic records and data tables based on a supplied structure or data sample but doesn’t offer the control over data variety and referential integrity required for complex testing scenarios.
As the provider of the industry’s leading Synthetic Test Data Automation platform, GenRocket believes there are essential requirements for an enterprise-scale deployment of GenAI tools for test data provisioning. As organizations experiment with GenAI and evaluate its use for application testing, it’s important to identify its role in the DevOps ecosystem and how the technology will function as a platform for data delivery in a global quality engineering environment.
Enterprise Scalability requirements can be categorized into two broad dimensions:
(1) The ability to ensure data quality while meeting complex data generation challenges
(2) Enterprise Scalability to fully manage the end-to-end data provisioning process.
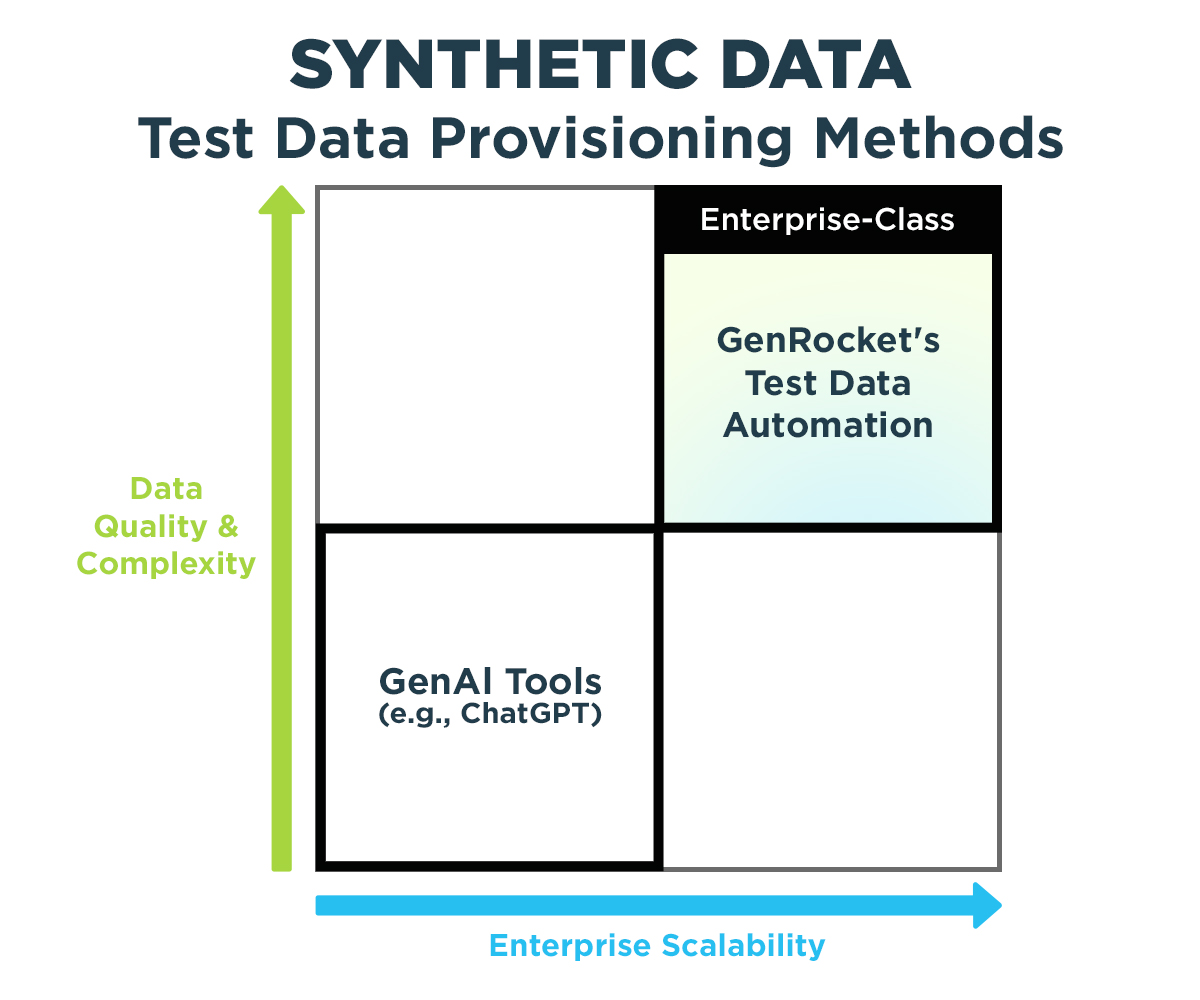
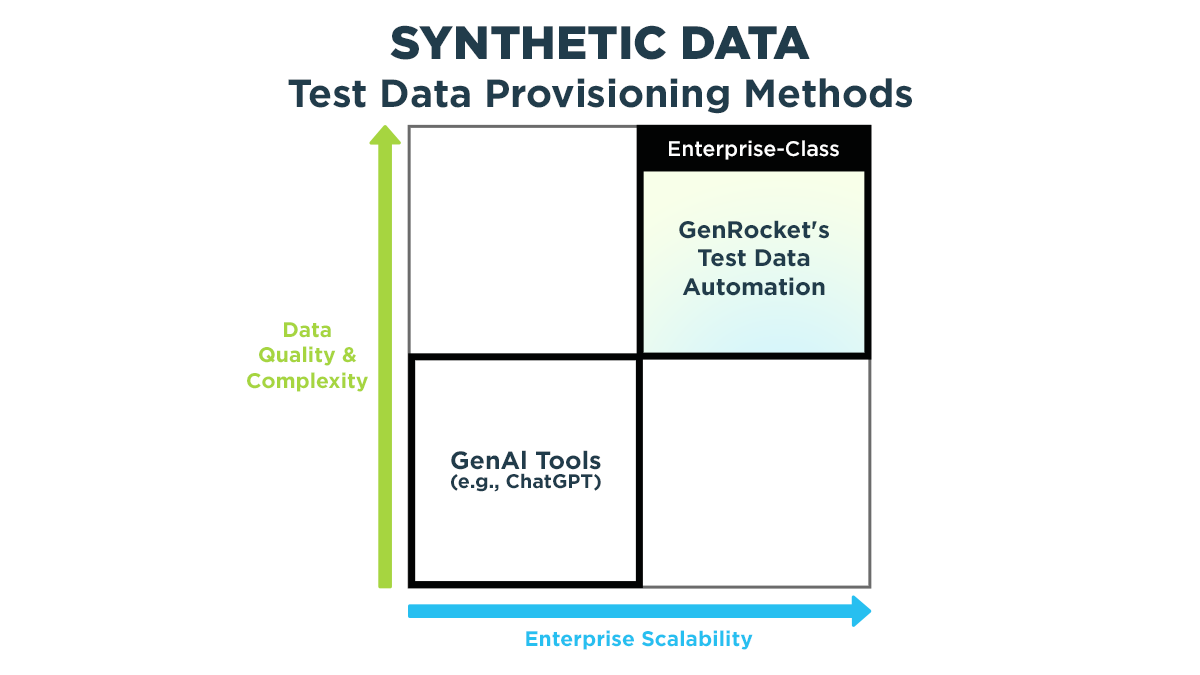
We will use the dimensions of Data Quality and the Enterprise Scalability of GenAI to compare it to a proven enterprise-class Synthetic Test Data Automation platform that has been globally deployed by GenRocket at more than 50 of the largest fortune 500 companies in the world. Part 1 of this series will focus on the impact of GenAI on synthetic data quality in a complex data environment. In part 2, the dimension of enterprise scalability as it relates to the deployment of GenAI technology will be examined.
The Dimension of Data Quality and Complexity
Data quality is the single most important aspect of synthetic test data generation. After all, the quality of the testing process and the code released to production is only as good as the data used for testing. Similarly, the accuracy of a machine learning model will only be as good as the data used to train the model. To ensure high quality test data is provisioned for the most complex software testing and machine learning requirements, important capabilities must be included in the data provisioning platform.
GenAI Limitations for Data Quality and Complexity
GenAI tools offer basic control over data variety through the creation of prompts and the use of sample data, but carry the risk that data gaps, hallucinations, and errors in referential integrity may be contained in the test dataset. That’s because all of the popular GenAI tools suffer from the same fatal flaw. Their Large Language Models (LLMs) are trained on publicly available data and are blind to the characteristics of internal enterprise information, resulting in a high percentage of inaccurate responses. Even after these tools are trained with internal data accompanied by knowledge graphs that provide contextual data relationships, their accuracy still hovers at around 50%.
Whether GenAI is producing synthetic data for decision-making, testing software quality, or training machine learning algorithms, its data quality, accuracy, consistency, and completeness are paramount.
A study was performed by data.world, a data catalog platform provider, to measure the accuracy of GenAI in a complex data environment. A series of natural language questions ranging from low to high complexity was used to query an enterprise-class SQL database using ChatGPT-4. The SQL schema used in the benchmark comes from the P&C Data Model for Property and Casualty Insurance, a standard model created by Object Management Group (OMG), a standards development organization. The goal was to measure the accuracy of the responses to a range of SQL queries that was produced using GenAI technology.
The results of the data.world benchmark showed that LLMs return accurate responses to most basic business queries just 22% of the time. And for intermediate and expert-level queries, accuracy plummeted to 0%. Their accuracy increased to 54% when questions are posed over a Knowledge Graph representation of an enterprise SQL database. Due to the lack of transparency in GenAI, it’s impossible to know how, where, and why those data quality issues occurred.
A conceptual model of this complex data environment is provided in the diagram below:
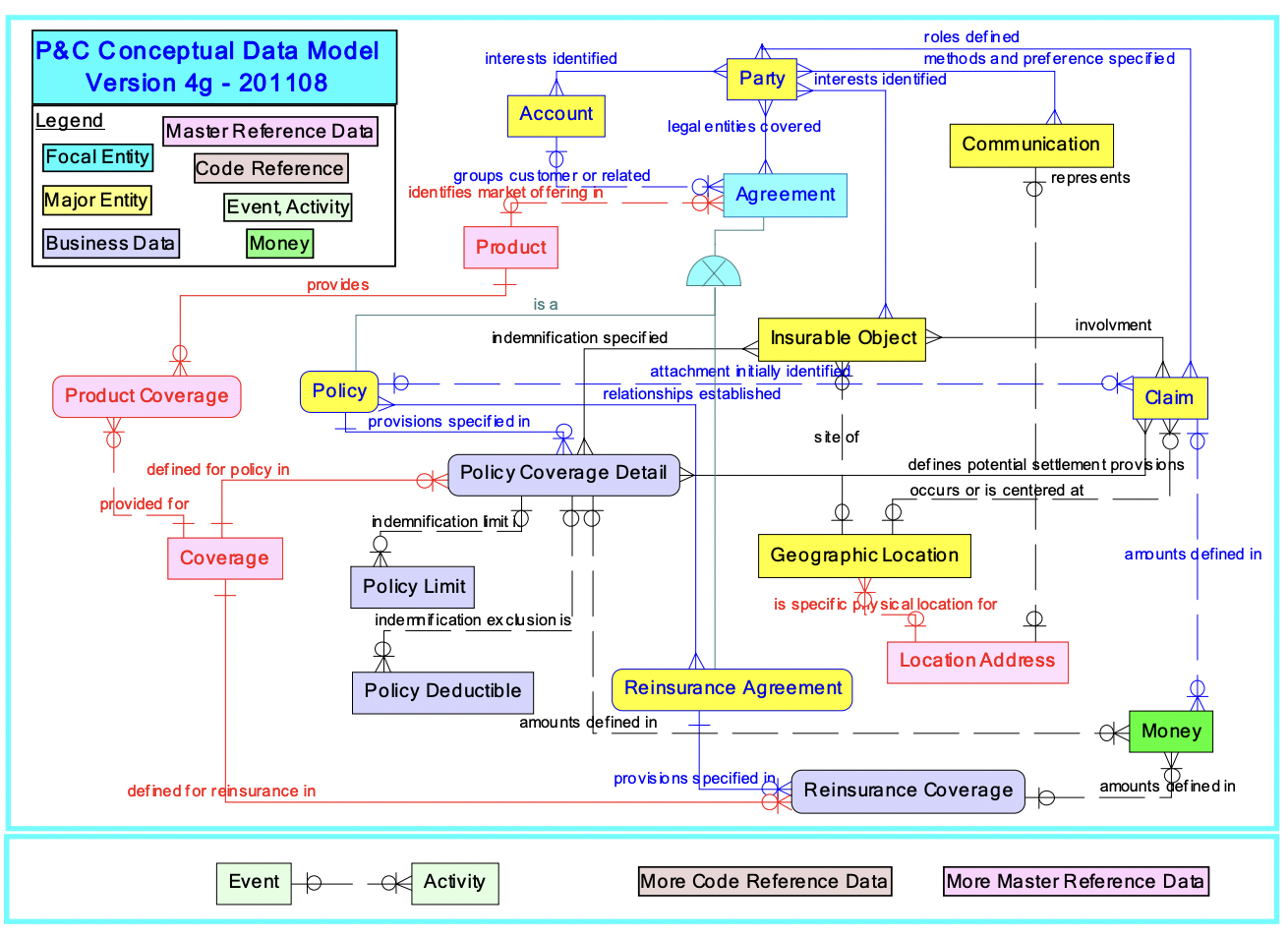
[SOURCE: A BENCHMARK TO UNDERSTAND THE ROLE OF KNOWLEDGE GRAPHS
ON LARGE LANGUAGE MODEL’S ACCURACY FOR QUESTION ANSWERING ON ENTERPRISE SQL DATABASES]
Here’s the key take-away: The accuracy of data produced by GenAI is determined by the depth of its domain knowledge and the complexity of the data environment it’s simulating. That’s a problem for most large enterprises where complex interconnected systems and mixed data environments represent the information fabric used in their data environments.
To assess the lack of transparency in GenAI models, Stanford University brought together a team that included researchers from MIT and Princeton to design a scoring system called the Foundational Model Transparency Index. It evaluates 100 different indicators of transparency for how GenAI and their LLMs operate. The study evaluated 10 LLMs and found the mean transparency score was just 37%.
All of this limits the ability of Generative AI to ensure the accuracy and completeness for complex synthetic data requirements. As a result, there is no way to ensure full coverage for test cases that rely on this data. And there is no guarantee that the same test data will be generated for each data generation event, limiting its use for parallel and regression testing where identical data must be run against different versions of code.
This begs the question “who in the organization will be responsible for the accuracy of the test data provisioned by GenAI”. Without the oversight of a resource with strong GenAI expertise combined with deep knowledge of the organization’s data environment to validate the output, the successful deployment of GenAI will be hard, if not impossible, to achieve.
GenRocket’s Enterprise-Class Capabilities for Data Quality and Complexity
The GenRocket platform provides total control over the volume, variety, and formatting options for data generation. It streamlines the process of provisioning the precise data required for a given test case by mapping its test data requirements to an executable Test Data Case.
With GenRocket, a synthetic test dataset can be generated with positive and negative values, patterns and permutations, predefined edge cases and boundary conditions, and the blending of queried production data with generated synthetic data. Highly sophisticated synthetic data scenarios can be designed as Test Data Cases for automated execution in a test case and combined into Test Data Stories and Test Data Epics for full-scale orchestration of complex data for integration and workflow testing.
GenRocket can apply sophisticated rules to control the accuracy and statistical profile of a generated dataset. This eliminates the possibility of hallucinations and ensures a balanced dataset without biases or data gaps. If required, specific data conditions can be amplified to improve the detection of under-represented anomalies (e.g., fraud detection) when training a machine learning algorithm. Test Data Cases are a flexible way to control and condition all aspects of the data needed for testing. And because Test Data Cases can generate the exact same data every time they are executed, there is no need to store, reserve, or refresh a shared synthetic dataset, just regenerate the data whenever it’s needed on-demand.
GenRocket’s synthetic data generation platform offers more than 700 intelligent data generators and over 100 data output formats to simulate any form of structured and unstructured data as well as legacy mainframe environments. These components are part of a constantly expanding library of data generation tools that are contained in a single modular platform. Additionally, GenRocket has been awarded a U.S. patent for systems and methods of data generation with referential integrity.
Part 2 of this series will assess the importance of lifecycle management across the end-to-end test data provisioning process and the impact of GenAI on this important enterprise scalability requirement.