

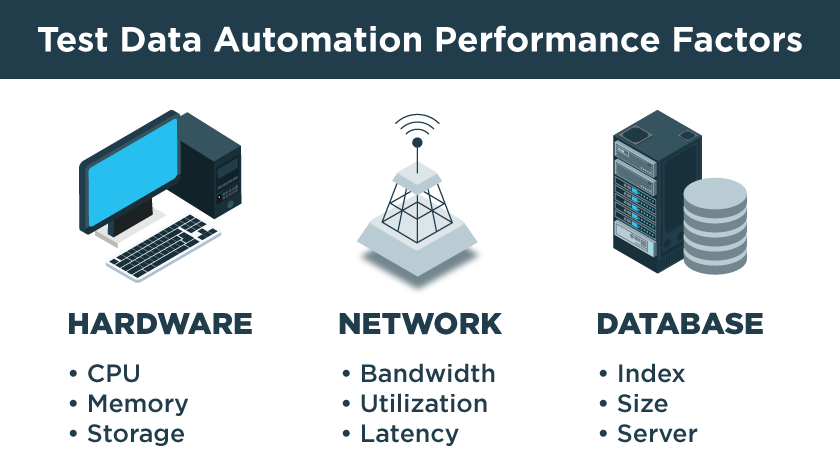
Software performance testing is a form of non-functional testing that’s critical to providing a great user experience and ensuring the stability and scalability of any software application under heavy load conditions. To fully exercise your code, you’ll need a high volume of test data to simulate the most demanding real-world operating conditions.
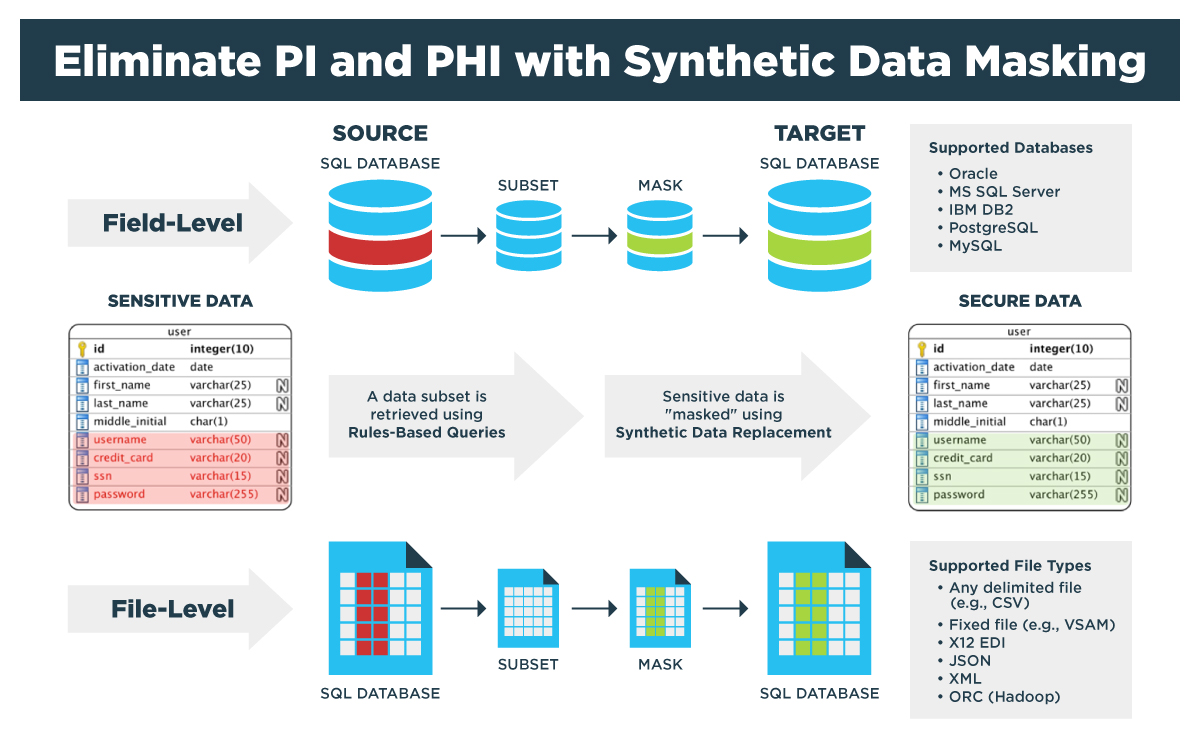
We are often asked if GenRocket can perform data masking. The answer is, “Yes, of course – and with ease.” But like many questions asked about synthetic test data, the simple answer belies a complex explanation of the advantages of synthetic test data over production test data. Here, we explain five issues with masked production data and how Synthetic Data Masking overcomes them.

The GenRocket Test Data Automation platform has been in development for more than 10 years with a vision of accelerating and automating the delivery of accurate, controlled test data into any testing environment.

The meaningful use of electronic health records (EHR) has been at the forefront of the healthcare IT conversation since the 2014 American Recovery and Reinvestment Act. As of 2019, the CDC reports that 89.9% of healthcare practices such as physicians’ offices are actively using at least some or all of an EHR management system.

The healthcare sector is on the verge of a revolution in data and analytics, but the advancement of data-driven decision making has been hampered by difficulties in updating legacy systems, as well as challenges stemming from disparate data sources. With the growing push to digitize patient and claims information, the evolution of healthcare data exchange standards has come a long way to address some of these problems, but not all of them.

Enterprise Metadata Management is technology used to centrally manage and deliver high quality data and trusted information for business analysis and decision-making. Metadata is often referred to as “data about data” and describes the content, governance, and structure of enterprise information. Metadata is often used to create data catalogs that aggregate, group, and sort multiple data sources to make them accessible for a wide variety of use cases.
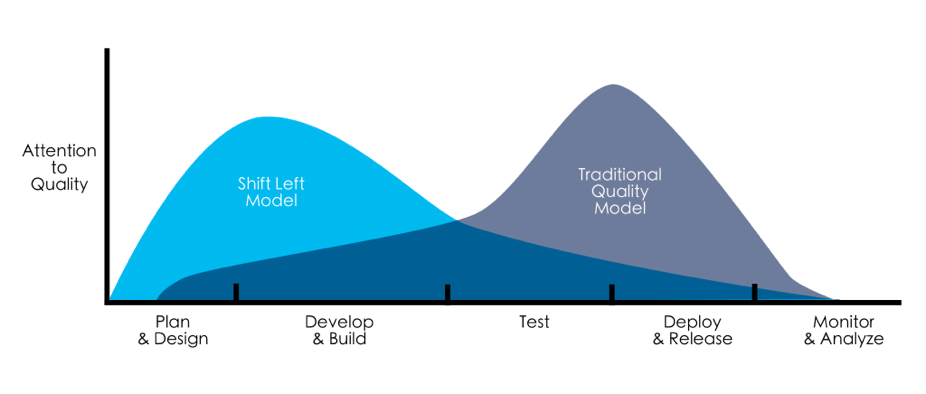
The strategy of Shifting left means performing software testing earlier in the SDLC so that defects can be detected when they are faster and easier to correct. Software bugs that escape to production can cost 100 times more to resolve than early in the product lifecycle.
Until recently, the global financial services industry (estimated at $22.5 trillion in 2021) has been slow to adopt cloud computing for its core processing functions. Entrenched legacy applications, uncertain cybersecurity risks, and regulatory compliance issues have all presented steep barriers to cloud adoption in the financial sector.