Realize the Power of Design-Driven Synthetic Data
GenRocket’s Innovative Paradigm for Test Data Automation
Today’s interconnected software systems pose challenges for development and testing teams when it comes to generating precise, scalable, and diverse test data for every phase of the software development lifecycle. Traditional Test Data Management solutions are falling short due to data security risks, low-quality data, and slow provisioning.
Risks and Limitations of Using Production Data in Testing
In enterprise-level quality engineering (QE) and quality assurance (QA), production data is often used to simulate real-world conditions in testing environments. While this approach ensures data realism, it introduces significant challenges related to data privacy, security, and data quality.
Data Privacy and Security Risks
Using production data in test environments exposes sensitive personal information such as patient records, customer details, and financial data. Even with data masking protocols in place, there’s a critical exposure window: sensitive data must first be copied into the testing environment before it can be masked. The main risks of masking production data include potential reverse engineering if the masking method is weak or predictable, and the likelihood of missing sensitive fields due to incomplete data discovery or misconfiguration. Additionally, multiple data copies are frequently created for various testing stages, increasing the attack surface for potential breaches. A single oversight can lead to compliance failures, regulatory penalties, and reputational damage.
Data Quality Limitations
While production data reflects real-world scenarios, it lacks predictability and coverage for specific testing needs. This limitation becomes problematic when testing for:
- Edge Cases and Boundary Conditions: Rare or extreme scenarios may not exist in production data.
- Business Rule Validation: Testing program logic often requires specific data patterns and permutations that may be absent in live datasets.
- Regression Testing: Consistent, repeatable test runs require data with known attributes and values, which production data cannot guarantee. The ideal scenario would be to use the identical test data to validate each version of code in a controlled testing environment.
- Negative Testing: by definition production data only provides happy path data and is unable to test the code for its behavior under negative test conditions
- New and Unique Data: When developing new features and modernizing legacy applications there is a need for comprehensive test data that simply doesn’t exist in the existing production environment.
Security Risks of Synthetic Data Based on Statistical Replication
Many synthetic data generation solutions attempt to solve the privacy and security risks by creating statistically accurate replicas of production data, however, production data still must be copied to a lower environment and statistically profiled prior to synthetic data generation which means sensitive data is exposed and there is an opening for a data security breach.
Data Quality Issues of Synthetic Data Based on Statistical Replication
Synthetic data based on statistical replication is data based on accurately reproducing a production database. A production data replica is great for statistical analysis but is not ideal for software testing. Production data is random, in an unknown state and only reflects existing patterns in historical data. Software testing requires specific data in a known state, for each test case that is executed. And production data lacks the volume, variety, permutations, and edge cases essential for comprehensive functional and non-functional testing. As a result, defects related to program logic, business rules, or complex system integrations can slip through undetected.
GenRocket’s Innovative “Design-Driven Data” Approach
GenRocket redefines how synthetic test data is created with its innovative “Design-Driven Data” methodology. Unlike synthetic data generation methods that rely on statistical replication, GenRocket models the required synthetic data set based on the meta-data associated with the production environment. This meta-data-driven model becomes the foundation for assigning intelligent data generators that can be configured to produce any required volume, variety or format of data that is needed.
Intelligent data generators are assigned to each data element to control the nature of the data generation process. Data generators can be used for basic tasks like generating names, addresses, and social security numbers. They can also be used to perform complex data generation tasks like generating all permutations for a combination of fields, or producing patterns, edge cases, or positive and negative values.
Data generators can be configured to perform calculations, apply Boolean logic, or conform to if/then relationships when testing business rules and transaction flows. They can be assigned a seed value to reproduce the exact same data for multiple test runs or provide stateful data when testing calculations and validating account balances.
GenRocket has a library of more than 700 intelligent data generators, and we are adding more all the time. Data generators produce data in a raw format that can be converted to virtually any output data format such as SQL, NoSQL, JSON, XML, fixed file formats and more. There are more than 100 data formats currently supported. New formats can easily be added to meet specific customer data requirements.

Test Data Cases, pre-configured instruction sets that are executed in real time by automated testing tools and frameworks are designed and stored in a Test Data Case Library. GenRocket doesn’t rely on storing massive testing datasets. Instead, it generates synthetic data at high-speed, on demand, creating only what the test environment needs at the moment of execution.
Because Test Data Cases are tiny compared to the size of entire production data copies, the expensive storage overhead required by production datasets (or a synthetic replica) is eliminated – as is the need to refresh the production data copy. And to fully realize the speed and efficiency of testing automation, Test Data Cases can be seamlessly integrated into continuous integration and delivery (CI/CD) pipelines. GenRocket handles diverse test data provisioning requirements with ease, offering dev and test teams a powerful platform for achieving all of their testing objectives.
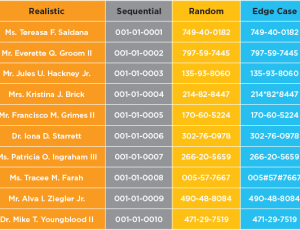
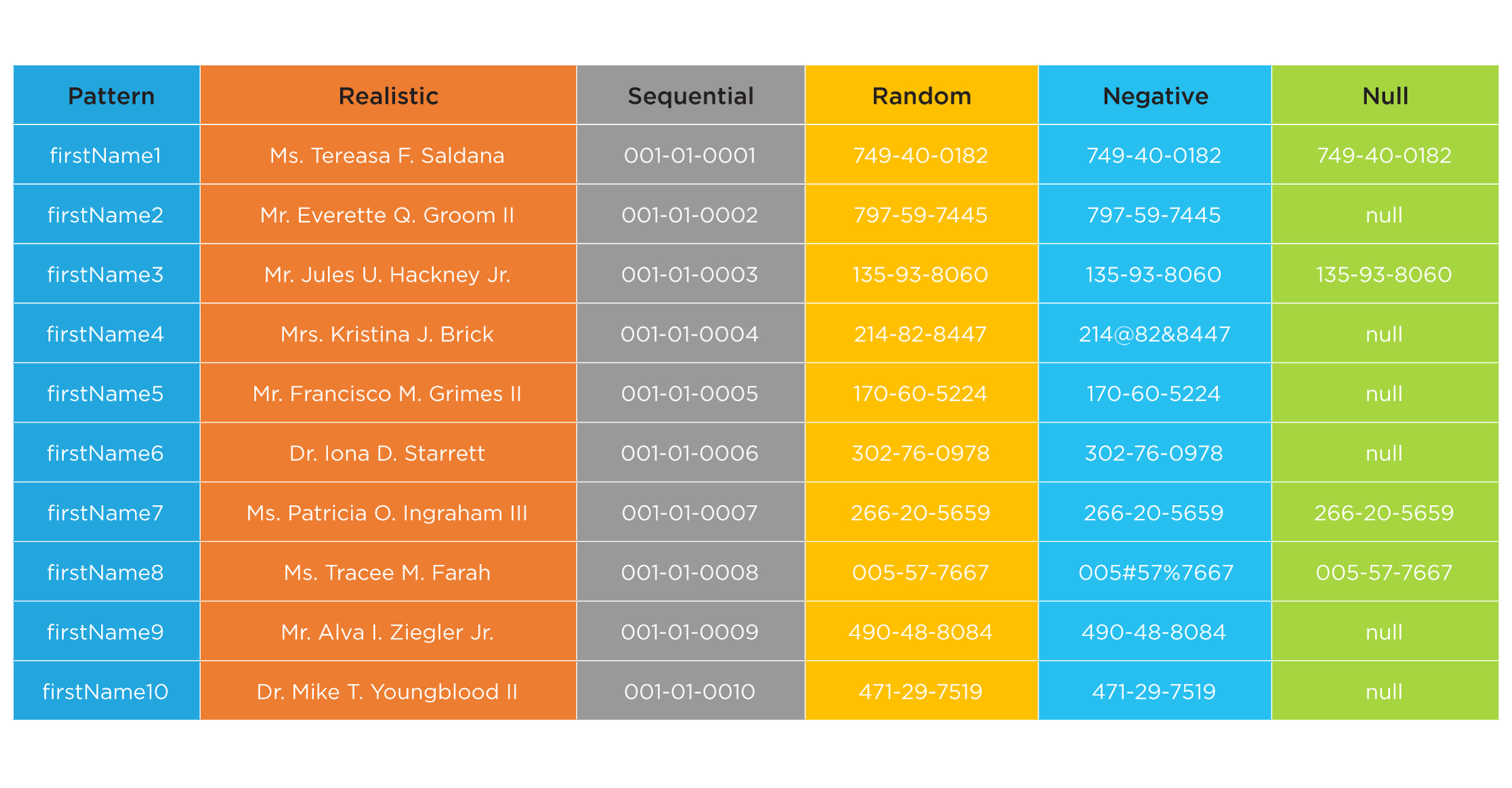
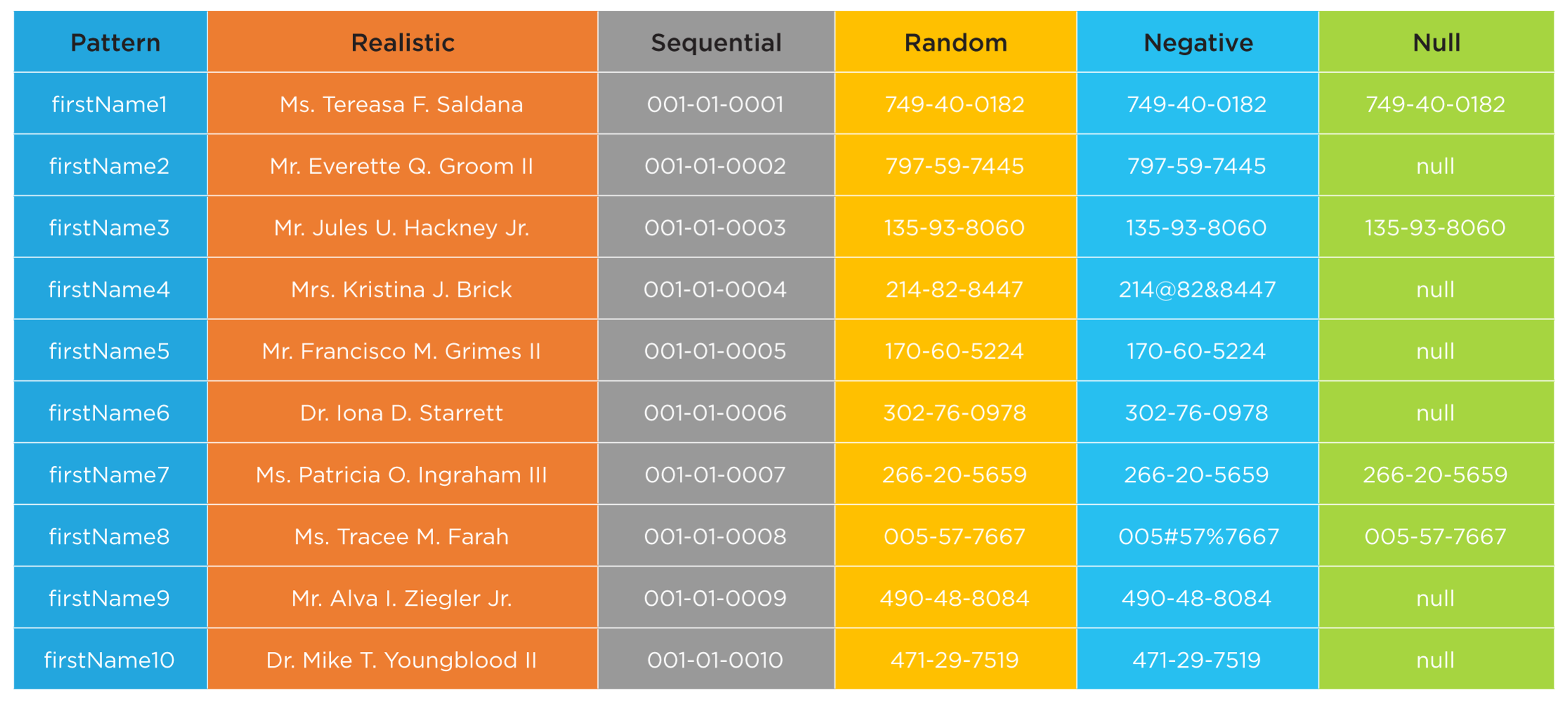
The Illustration below provides an example of controlled and conditioned synthetic data generated by a Test Data Case. This example includes patterns, realistic data values, sequences, random data, negative data and null data. Using Test Data Cases, GenRocket can be configured to generate an unlimited volume, variety, and format of synthetic test data to meet any test case requirement.
GenRocket Architecture: Test Data Case Management
To allow developers and testers to design any data, including data that does not exist in production databases, GenRocket provides extensive Test Data Case Management capabilities.
Test Data Cases (G-Cases): An executable instruction set to generate a specific set of data required by a test case.
Test Data Rules (G-Rules): The ability to apply one or multiple rules to the data that is generated by the Test Data Case.
Test Data Queries (G-Queries): The ability to query and blend enumerated production data values with synthetically generated data for data validity (e.g. blend a real customer account number with other synthetic data values).
Test Data Stories (G-Stories): The ability to aggregate multiple G-Cases into a comprehensive series for Test Data Cases, ideal for system testing.
Test Data Epics (G-Epics): The ability to combine multiple G-Stories to orchestrate large-scale testing initiatives or to validate end-to-end workflows. This combination of foundational components and intelligent automation allows teams to adapt test data provisioning to meet the needs of any category of testing.
The following diagram illustrates one potential use of the Test Data Case Management components to create a hierarchical organization for testing an entire enterprise application and its data environment:
How GenRocket Maps Test Data to Each Test Case Objective
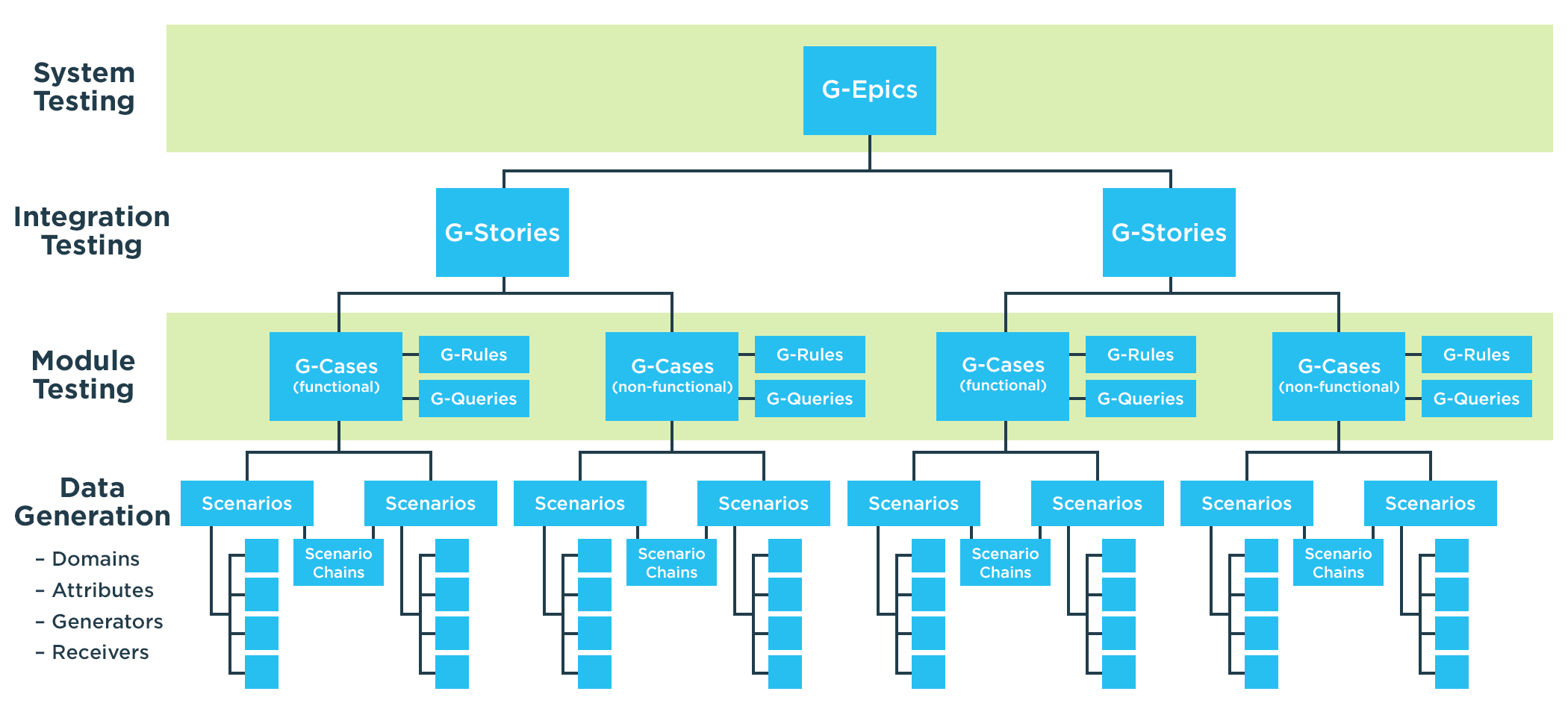
This visual representation underscores the scalability and adaptability of GenRocket’s synthetic test data automation framework, empowering teams to tailor their test data strategies to meet any requirement. Additionally, this modular approach allows for complex data environments to be simulated with ease. Collectively, an organized collection of Test Data Cases represents a Test Data Project, a library of test data designs that can be reused, repurposed, and version controlled for efficient and accurate on-demand test data delivery.
Test Data Cases (G-Cases), can be requested by developers and testers using a self-service portal and quickly modified on-the-fly using a self-service component called G-Questionnaire. All G-Cases are stored in a distributed repository where schema changes made to any element of a Test Data Project in one location is automatically updated in all other locations. This enables global scalability of distributed self-service for rapid test data provisioning.
Transitioning From Using Masked Production Data to Synthetically Generated Data – A Unified Data Provisioning Platform
Recognizing that enterprises can’t adopt new approaches overnight, GenRocket offers a unified data provisioning solution that combines traditional test data management technology with advanced synthetic test data automation technology. This single data platform enables our customers to smoothly transition from test data based on production data to Design-Driven Synthetic Data over time.
GenRocket’s unified test data provisioning approach gives organizations the best of both worlds, allowing them to:
- Continue using production data for certain legacy tests or familiar business processes.
- Gradually introduce synthetic data, starting with specific use cases and expanding as their expertise grows.
This hybrid model allows customers to control their own pace of adoption minimizing disruption to existing organizational processes. Teams can seamlessly integrate synthetic data alongside masked production data, ensuring continuity while improving data privacy and expanding test coverage.
Why GenRocket’s Approach Matters
By adopting GenRocket’s test data automation platform, enterprises can eliminate data privacy risks while gaining full control over test data quality. Developers and testers can design and provision precise data sets tailored to specific test objectives, improving both functional test coverage and security compliance. As organizations grow comfortable with synthetic data, they can scale its usage to reduce their dependency on production data entirely.
With GenRocket’s flexible, scalable, and secure approach, enterprises can modernize their test data strategy while ensuring seamless integration into their existing testing workflows. The result is better data, safer testing, and faster, more reliable software releases.