Synthetic Data Redefines the Test Data Lifecycle
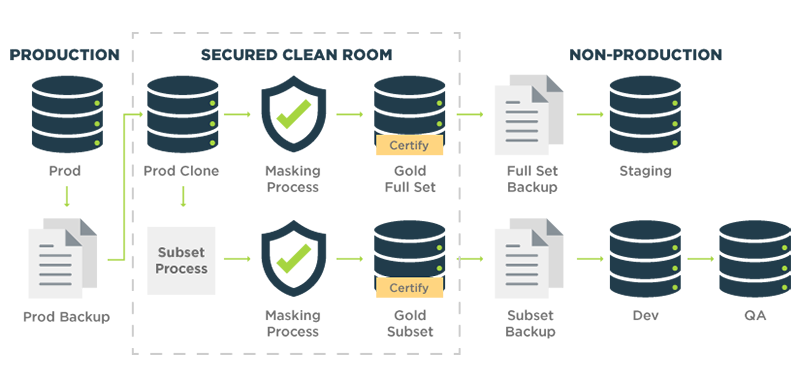
In traditional Test Data Management (TDM), the test data lifecycle is based on the premise that some or all data used for testing is sourced from production. A full or subsetted copy of a production database is transferred to a clean room where it is examined for personally identifiable information (PII) and masked or anonymized before being transferred to a non-production environment for testing.
This process results in a Gold Copy of test data that can used for white box testing by developers or functional and non-functional testing by testers. A full test data set may also be stored in a staging area to provide a sandbox for system testing prior to releasing new code into production.
However, during test operations, test data may be modified by an application under test or become stale rendering the data invalid for subsequent testing. Over time, database tables and their relationships can change, and new formats may be introduced into the application environment. This means test data must undergo an ongoing data refresh process.
As a result, the use of production data requires a strict lifecycle management regimen to ensure test data is continuously:
- Secure and compliant with all data privacy laws
- Up to date in terms of its data structure and formatting
- Refreshed after each test run and returned to its original state
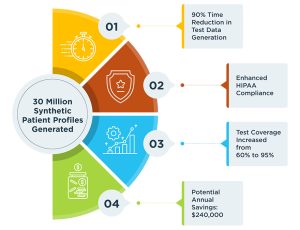
Even after these data management tasks are performed, there is still work to be done to get production data ready for testing. The QA team members or a dedicated data team must mine the production data copy to find the right variety and volume of data needed for specific test cases. For some organizations the required data combinations and variety are not available in the production data copy up to 50% of the time which results in manual (spreadsheet) data creation to build the data that is required.
Many TDM systems provide a portal for testers to query and “reserve” datasets. Data reservation is an important capability of TDM systems because developers and testers often need unique data for their tests and need to “reserve” data sets that are only used for their test cases.
Often, testers will run their test cases against a shared production data copy. With this shared test data model there is a significant risk that test data in the production copy is modified as tests are run. Since tests in this model are being run in a “polluted” vs. clean data environment there is a significant risk of invalid tests being run. This is why many organizations “refresh” their production data copies. However, managing frequent data refresh cycles can be cumbersome and costly in terms of time and organizational resources. Unfortunately, it’s required to ensure the integrity of the data being used for testing.
The Transition to Synthetic Data Streamlines the Test Data Lifecycle
Many organizations, and especially those in financial services, are mandating the broad use of synthetic data for testing to ensure data privacy. By deploying Test Data Automation (TDA) to generate real-time synthetic test data, many of the data management tasks described above are no longer necessary. Synthetically generated test data is a fundamentally different paradigm than sourcing data from a production environment. Here are some of its key differences:
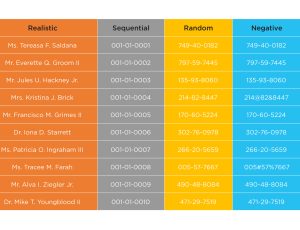
- Synthetic data is 100% safe and secure, removing the risk of exposing any PII
- Data profiling and masking are not needed for 100% secure synthetic datasets
- Data volume and variety are pre-defined, to provide the exact test data needed
- Data subsetting is no longer required because right sized test data sets are available to all testers
- Data reservation is not needed as unique data can be generated for every test case
- Data refresh is not needed because a fresh copy of data is generated for each test case
In GenRocket’s TDA platform, synthetic test data is designed in the GenRocket Cloud and generated when it’s needed on-prem using the GenRocket Runtime. Test data instruction sets, called Scenarios, and configuration files, called Test Data Cases, contain everything needed by the GenRocket Runtime to generate a pre-defined test dataset in seconds. Scenarios and Test Data Cases specify the required patterns, combinations, and permutations of data and generate any volume of data. And GenRocket ensures that all synthetic datasets are referentially intact and properly formatted to match the target data environment.
This diagram illustrates the service architecture of GenRocket’s Test Data Automaton platform.
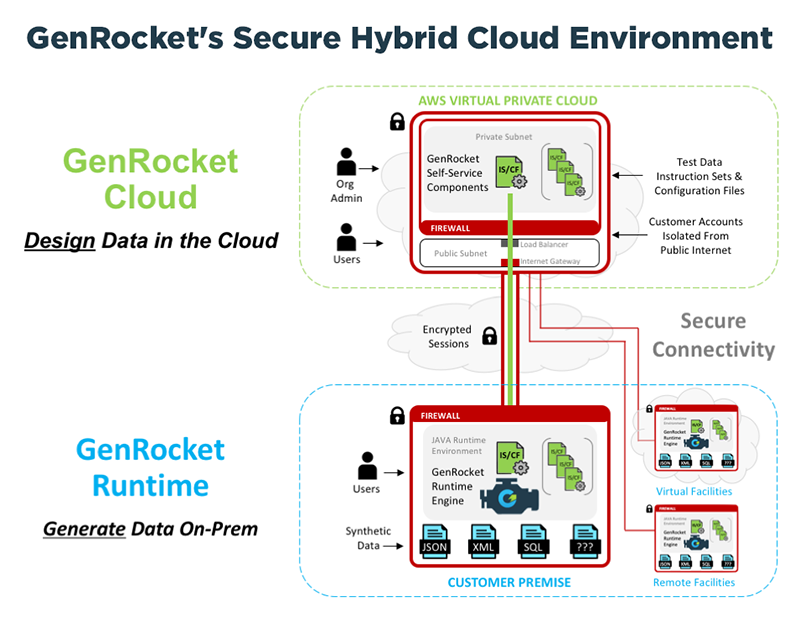
QA and Dev teams can satisfy all test case requirements with synthetic data or augment the use of production data with blended synthetic data. GenRocket technology provides a seamless and scalable path for QA & Dev organizations to gradually expand their use of synthetic data. This approach allows them to eliminate PII from the test environment while increasing coverage with greater test data variety (e.g., positive, negative or edge case scenarios).
GenRocket Instruction Sets and Configuration Files are synchronized to a shared repository under version control that allows testers to re-use, repurpose, or re-run tests with a fresh copy of data whenever it’s needed. Testers can use the GenRocket Self-Service module to select a pre-built test data scenario or design a new one. Self-service eliminates the wait-state associated with requisitioning test data from production and puts control over the data needed for testing in the hands of the tester.
Understanding GenRocket’s Test Data Lifecycle
The Test Data Lifecycle looks very different with synthetic data and the use of Test Data Automation when compared to the traditional TDM lifecycle.
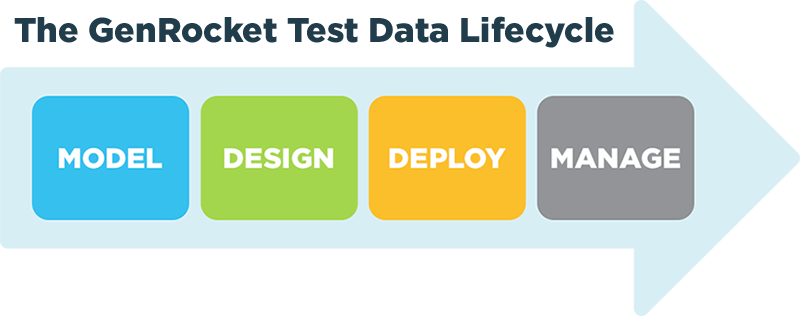
With GenRocket, a 4-stage methodology streamlines and accelerates this lifecycle.
Model: GenRocket provides 11 different methods for testers to model their data environment, including importing a database schema to reproduce referentially intact test data.
Design: Self-service modules guide testers through the test data design process. If testers can imagine the test data needed for testing, they can generate it synthetically.
Deploy: Test Data Scenarios can be deployed in just about any data format (e.g. XML) into a CI/CD pipeline and scheduled to generate synthetic data in real-time, on-demand and during test execution.
Manage: All test data instruction sets and configuration files are stored in a shared repository where they are version controlled and automatically refactored to reflect any changes to their design.
G-Refactor is intelligent automation inherent in the GenRocket platform. It ensures that changes made to any of the components in a Test Data Scenario is automatically updated. That way, when revisions to the data model occur, the system can automatically update the GenRocket project environment with those changes. GenRocket allows QA and Dev teams to redefine the test data lifecycle with a more automated approach for provisioning data.
-
- Because test data is synthetic data, there is no longer a need to profile and mask the data to make it ready for use in a non-production environment.
-
- Because testers can pre-configure a test dataset to produce any volume or variety of synthetic data, there is no longer a need for data mining and data subsetting.
- And because GenRocket automatically refactors changes to test data configuration files and generates a fresh copy of data for each test run, there is no longer a need for data reservation and refresh.
The synthetic test data lifecycle is a powerful change to traditional test data management. It leverages the power of Test Data Automation to accelerate the process. It unlocks the flexibility of synthetic data to meet any test data challenge. And it removes the risk of using PII for testing and the requirement for masking and managing production data during the provisioning process. If you would like to learn more about the synthetic test data lifecycle and the power of Test Data Automation, request a demo with a GenRocket TDA expert.