Take Your Software Performance Testing Strategy to the Next Level
Software performance testing is a form of non-functional testing that’s critical to providing a great user experience and ensuring the stability and scalability of any software application under heavy load conditions. To fully exercise your code, you’ll need a high volume of test data to simulate the most demanding real-world operating conditions.

Performance testing is a perfect use case for GenRocket’s Test Data Automation platform. Out of the box, the GenRocket runtime engine generates approximately 10,000 rows of data per second in more than 800 output data formats. For many test cases, 10,000 data rows are sufficient. However, to meet comprehensive performance and load testing requirements, billions of rows may be needed to test the system thoroughly and adequately. And while GenRocket does indeed produce the volume and variety of test data required for most categories of testing at high velocity, there are ways to speed up the process of generating extremely high volumes of data for any type of load and performance testing.
Here are three ways in which you can speed up the production of synthetic test data when producing more than a million records, as well as some helpful tips to ensure GenRocket works at optimal efficiency.
The Importance of Comprehensive Performance Testing
Before delving into how GenRocket supports high volume synthetic data generation for performance testing, let’s address a bigger question: why conduct load and performance testing?
Some may argue that if a system works well with 10,000 records it will work equally as well when tested with 1,000,000 records. However, we have seen several instances in which systems have crumbled under heavy performance and load testing. In each case, utilizing an average amount of data for the test would not have uncovered the system errors, response time degradation or stability issues that were not apparent until a high volume of data was tested in the system.
A system may be able to handle 10,000 queries or transactions per minute but 10,001 is the proverbial “straw that broke the camel’s back.” Unfortunately, without testing a system’s limits, this may not be known until the system goes online and fails under real-world conditions.
A recent example is the Ticketmaster Taylor Swift concert ticket fiasco. Angry fans found the online system crashing during checkout, forcing them to return to the front of the virtual queue and losing tickets for choice seats at Swift’s upcoming concert. According to one source, Ticketmaster was prepared for up to 2 million hits to their site, but bots and fans simultaneously attempting to purchase tickets swelled visits to over 14 million, causing the site to crash.
Was this due to insufficient infrastructure resources or did the system buckle under the extremely high volume of people checking out simultaneously. Perhaps load and performance testing could have unearthed some of the issues that caused the system to crash. Due to the pending lawsuit, Ticketmaster is not providing details of their ticketing system failure.
Make sure that your systems won’t buckle under similar pressure by improving your load and performance testing. With GenRocket synthetic test data, you will always have the variety, volume and velocity of controlled and accurate synthetic data required for testing. And if you need billions of rows of test data or even more, we’ve got you covered.
Provisioning High-Volume Synthetic Test Data at Speed
GenRocket users have several platform capabilities available to produce high volume synthetic test data at speed. These include:
- The Partition Engine
- The Scenario Thread Engine
- Bulk Load Receivers
Partition Engine
As the name implies, the Partition Engine balances the load across multiple GenRocket instances running within a given server. If you are generating extremely high amounts of test data, it can be partitioned across multiple servers, each running multiple GenRocket instances. We have seen customers use the Partition Engine to successfully handle millions, billions, and even trillions of rows of data.
How does the Partition Engine work? Synthetic data instruction sets are split across multiple threads and data is simultaneously generated on each thread. Test data volume is evenly distributed across all instances and processed in parallel. Users must have the appropriate system configuration to support the number of threads executed at the same time.
Additionally, the data values must be unique and increasing across all instances in a sequential fashion. For example, if you need to generate 1,000,000 records, the Partition Engine may spread Records 1-20,000 on Thread 1, 20,001 – 40,000 on Record 2, and so on.
If data dependencies are present, there are special steps to follow. It is important to follow them in order. First, you must generate data for the Root Domain. Then, generate data for each Domain that other Domains are dependent on. Lastly, generate data for each remaining Domain that has no dependencies.
There’s an additional trick you can use to speed up data generation when using the Partition Engine. There is a built-in flag that, when set to true, looks up the Parent/Child relationship to determine if a particular Generator with a parent is not being referenced by any of the child records. If not, it turns off Generators for Attributes that are generating data and not being referenced by the child since they aren’t needed. This speeds test data generation.
Scenario Thread Engine
Like the Partition Engine, the Scenario Thread Engine enables synthetic test data generation at high volume and with high velocity. Instead of partitioning data generation to simultaneously produce sequential data, it executes multiple Scenarios within a Scenario Chain or Chain Set across multiple threads. And, unlike the Partition Engine, the data generated via the Scenario Thread Engine does not have to be sequential. However, data from one Scenario cannot be dependent on data from another Scenario.
The great thing about the Scenario Engine is that you can run multiple Scenarios at once – and if the system is done running one, it immediately looks for another to run. That also saves time when generating high volumes of data.
Bulk Load Receivers
In GenRocket’s component architecture, Receivers are the components that generate synthetic data in the desired format of the target data environment. As the name implies, Bulk Load Receivers can generate and load huge amounts of data into a database very quickly. They utilize files containing delimited data and a file of what the delimited data looks like. From there, they receive and recognize that the file needs to be looked at the for the data and then “slam” it into the database very quickly.
Other Ways to Improve Speed
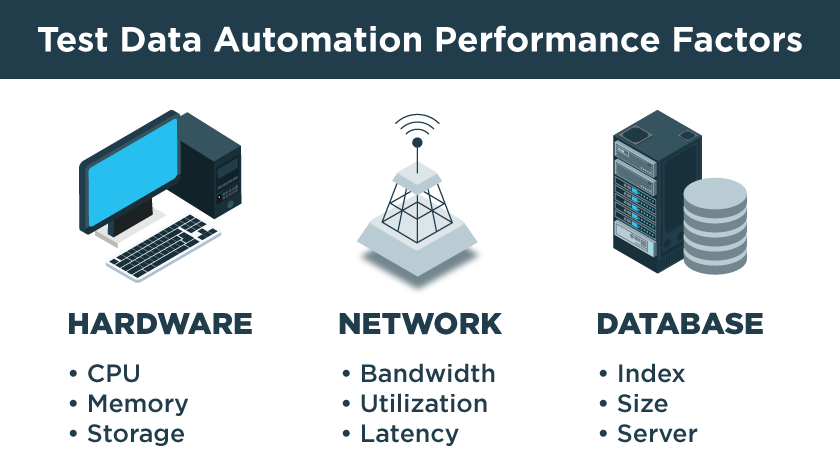
There are other ways to improve synthetic data production speed with GenRocket. Three environmental factors impact the performance of the GenRocket engine – the client’s hardware environment, the network environment, and the database server environment. Each factor plays a role in performance. Optimizing the speed of test data generation requires attention to each one.
You can learn more about the many ways you can optimize the speed of your test data generation operating environment by reading the knowledgebase article referenced below.
When Is Load and Performance Testing Critical for Applications?
As we have seen from the Ticketmaster example, ensuring that testers have the test data variety and volume required for adequate load and performance testing is critical. Other examples we have seen from our customers include:
- Training databases with machine learning: When training a machine learning algorithm, the higher the data volume, the more reliable the outcome. In this use case example, one billion rows of training data based on sophisticated rules and statistical data distributions for a tax fraud detection system were generated to train the model. The system was able to successfully train and test every possible aspect of the tax fraud detection system.
- Insurance claims transactions are high volume applications where results are critical. GenRocket’s load and performance testing data enabled high volume generation of complex data structure like the deeply nested XML data format used for X12 EDI insurance claims transactional data for thorough end-to-end testing.
With Synthetic Test Data Automation, total control over data variety, volume, and velocity are all within reach. The GenRocket TDA platform makes producing high volume synthetic test data for load and performance testing not only possible, but easy and efficient. The result is better testing for delivering more robust applications.
You can learn more about GenRocket’s performance optimization capabilities by reading this knowledge base article: How to Optimize Test Data Generation.
And if you want to see the GenRocket platform in operation, schedule a personalized demonstration with one of our synthetic data experts.