Test Data Management is Switching to Synthetic Data Generation
The paradigm of test data management is being flipped upside down to meet the new needs for agile testing and regulation requirements. Let’s take a look at the current state of test data management and where it is going.
Classic Test Data Management: Pruning Production
The first iteration of test data management solutions focus on a top-down approach. These solutions prune and mask production data which can be delivered to testers and engineers. This was an important first step to achieve higher quality testing and security. These solutions solve many problems but have introduced bottlenecks of their own that prevent teams from achieving continuous testing in today’s agile world:
- Creation/Delivery of Test Data is too slow: Pruning test data is a slow process which result in wait times of days or weeks for testers to start testing.
- Low quality test data: Delivered test data sets are not in the correct format, bulky, and require testers to manually modify the data to meet their scenario needs.
- Centralized process: Companies have to hire a centralized team to create or prune data for their entire testing organization.
The Future of Test Data Management: Synthetic Generation
Solutions today need to remove these bottlenecks and create test data management for agile testing:
- On-Demand Data: The test data needs to be generated on-demand in real time for each tester. This decreases the wait time of weeks or days for test data to just minutes.
- High Quality Test Data: Testers need to easily generate small, efficient, test data to meet each test case. This decreases the wait time to kick off each test case.
- Decentralized (Self-Service) Process: Any tester can generate the test data they need on their local machine. Companies no longer need resources to prune and manage test data which leads to significant cost savings.
Regulations Changing the TDM Paradigm to Synthetic Generation
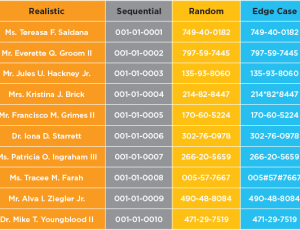
The coming EU General Data Protection Regulation does not allow personal data to be exposed in testing environments. You can see their definition for personal data below:
Any information related to a natural person or ‘Data Subject’, that can be used to directly or indirectly identify the person. It can be anything from a name, a photo, an email address, bank details, posts on social networking websites, medical information, or a computer IP address.
This is also not a regulation you can take your time adapting to: non-compliance can result in a fine of 4% annual global turnover or €20 million. To meet this regulations requirement and still be able to test your software you need to be able to generate a significant portion of your test data synthetically.
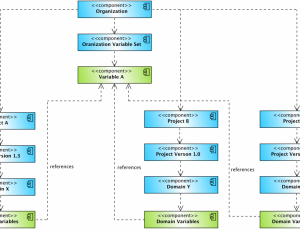
GenRocket: Patented Technology for Synthetic Test Data Generation
So, why haven’t other solutions shifted to a purely synthetic test data generation model before? The reason comes down to three requirements from testing organizations:
- The system would need to be able to generate any possible data.
- Along with generating any possible data, it would have to create the test data with full referential integrity.
- The system would need to be able to generate small to large amounts of data fast enough to meet testers tight deadlines.
Our Chief-Architect and Co-founder, Hycel Taylor, invented a system and method to achieve these requirements and created a system for test data generation that was not previously possible. We liked his invention so much we decided to patent it (Patent #9,552,266 B2 for Systems and methods for test data generation) and were awarded it on January 24, 2017.

At the time of writing this blog, there are only 310 days until GDPR is enforced. If you don’t already have a synthetic solution in place, why not take a look at GenRocket to shift from pruning to synthetic test data generation today.