Why Traditional Data Masking is Evolving to Synthetic Data Masking
We are often asked if GenRocket can perform data masking. The answer is, “Yes, of course – and with ease.” But like many questions asked about synthetic test data, the simple answer belies a complex explanation of the advantages of synthetic test data over production test data. Here, we explain five issues with masked production data and how Synthetic Data Masking overcomes them.
Five Issues with Production Data Masking
Although masked production data is the industry norm for producing privacy-protected test data, there are several problems associated with the process and its subsequent test data outputs. These issues or challenges may be summarized as follows:
-
- Security: Masked production data requires access to production data tables which may contain personally identifiable information (PII) or personal health information (PHI). Although masking obscures PII or PHI, the sensitive data is exposed during the masking process. This creates an unacceptable level of risk for many companies.
-
- Speed: Masking production data takes time, which increases test cycle time and can hinder a QA team’s ability to test with speed. Depending on how many fields need to be masked, and the volume required for testing, the time it takes to fully mask production data may create unacceptable delays in project timelines.
-
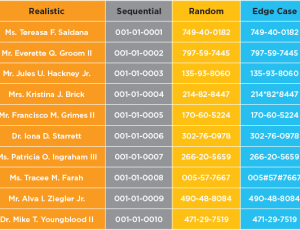
- Variety: The traditional data masking process copies a subset of live production data and obscures any PII or PHI. However, the selected dataset may not contain the required data variety to ensure adequate test coverage. By its nature, production data lacks negative values and may contain only a handful of records with critical boundary values for testing edge cases. And it may not contain certain data combinations that can trigger invalid results or create a poor user experience. Testing all data combinations and permutations is necessary to catch these unforeseen defects before they escape to production systems.
-
- Volume: Utilizing masked production data for testing can place limits on the volume of data available for testing. If a testing team needs 50 million records for load and performance testing, but only one million records exist in the masked dataset, the data will need to be augmented. That usually means cloning the dataset multiple times and using additional server resources. This is both cumbersome and costly.
-
- Other Limitations: Production data for new applications might be limited in scope or even non-existent. Testers would then be forced to create test data manually or develop scripts that randomly generate “dummy data”. And the use of production test data for training machine learning algorithms introduces its own unique set of problems such as limitations on the high data volumes need for accuracy and the biases that are often baked into production data that impact the performance of the model.
The Benefits of Synthetic Data Masking
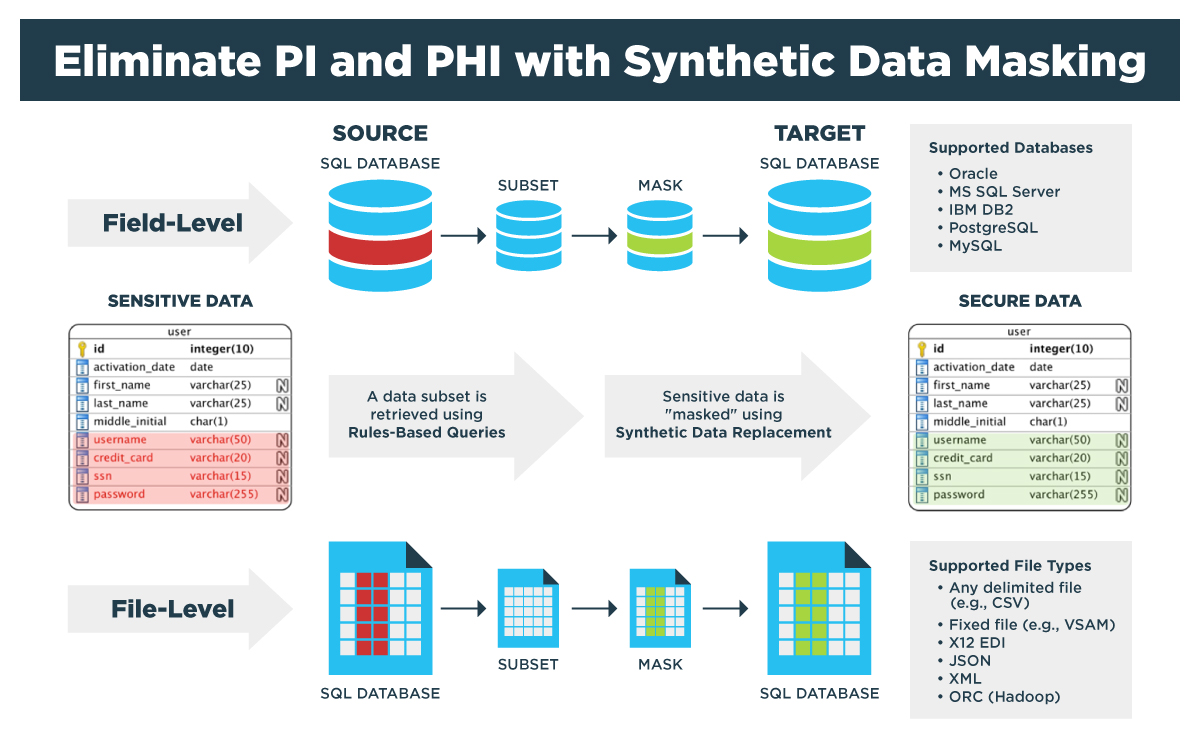
Synthetically masked test data offers many benefits when compared to the use of masked production data. The GenRocket solution for synthetic data masking is illustrated in the diagram below. It shows a process that is similar to traditional data masking in that a data subset is retrieved from a production data source using rules-based queries.
However, in synthetic data masking, sensitive data is replaced with synthetic data instead of the traditional approach of accessing and anonymizing the data. This is accomplished without accessing any sensitive data and allows the synthetic replacement values to be configured and controlled during the data generation process to allow more comprehensive testing.
The synthetic data masking process can be performed at the field-level by modeling and querying any popular SQL database, or it can be performed at a file-level by selecting specific columns to be replaced with synthetic data or copied as a subset into a target dataset.
For all five issues and limitations of production data masking described above, synthetic data masking is superior in its ability to provide guaranteed security along with the volume, variety, and velocity of test data that teams need to maximize test coverage and reduce cycle time.
-
- Security: Masked production data requires direct access to the original source database to identify and obscure sensitive information. Conversely, GenRocket’s synthetic data masking solution never needs to access sensitive information in a production database. Instead, metadata that defines the database structure (e.g., the database schema) is used to model and generate synthetic data that is equally accurate and realistic through the execution of a Test Data Case.
A Test Data Case is a small instruction set that controls the synthetic data masking process in the GenRocket Test Data Automation platform. Any tester or developer can download pre-configured Test Data Cases and execute them to generate secure, controlled synthetic test data in the required database format on-demand.
GenRocket ensures that absolute security is maintained over the original source files because the original files are never accessed by GenRocket. This is of great benefit for all industries who value data privacy and protection but especially industries such as financial services and healthcare for which hefty fines and penalties may be levied on companies who expose PII or PHI.
- Security: Masked production data requires direct access to the original source database to identify and obscure sensitive information. Conversely, GenRocket’s synthetic data masking solution never needs to access sensitive information in a production database. Instead, metadata that defines the database structure (e.g., the database schema) is used to model and generate synthetic data that is equally accurate and realistic through the execution of a Test Data Case.
-
- Speed: GenRocket’s synthetic data masking solution produces abundant data in any volume, variety, or format within seconds. This ensures that testing is never delayed as it can be when waiting for masked production data. GenRocket can produce masked synthetic test data within seconds and generate millions of rows within minutes. Each Test Data Case contains a blueprint for the structure of the data and the rules that control the patterns and permutations of data, in the volume and format needed for a given test case. GenRocket holds the only US patent for generating synthetic data with full referential integrity.
-
- Variety: With traditional data masking, the variety of data is limited to what’s available in the production data subset. However, with the use of synthetic data, dev and test teams can specify any type of data needed for negative testing, boundary value testing, combinatorial testing, or functional testing of business rules in the application under test.A Test Data Case can also be used to query a production database to retrieve a desired subset of non-sensitive data, replace its PII/PHI with synthetic data equivalents, and augment the subset with synthetic data to cover all possible data variations. Queries can be used to retrieve enumerated values, like customer account numbers or medical diagnostic codes, that are key to validating the code that relies on them. GenRocket makes it easy blend production data with synthetic data to maximize test coverage and identify software defects.GenRocket can generate synthetic data in the following database types and file formats:
Supported Databases
- Oracle
- MS SQL Server
- IBM DB2
- PostgreSQL
- MySQL
Supported File Types
- Any delimited file (e.g., CSV)
- Fiex file (e.g., VSAM)
- X12 EDI
- JSON
- XML
- ORC (Hadoop)
For testing new applications, database structures or file types, synthetic data masking offers a highly flexible alternative whereby a developer can simply request the data they need and create or modify a Test Data Case to generate the required data volume and variety. Synthetic data masking is the perfect solution for new application development or training machine learning algorithms with high quality synthetic data in high volume.
- Variety: With traditional data masking, the variety of data is limited to what’s available in the production data subset. However, with the use of synthetic data, dev and test teams can specify any type of data needed for negative testing, boundary value testing, combinatorial testing, or functional testing of business rules in the application under test.A Test Data Case can also be used to query a production database to retrieve a desired subset of non-sensitive data, replace its PII/PHI with synthetic data equivalents, and augment the subset with synthetic data to cover all possible data variations. Queries can be used to retrieve enumerated values, like customer account numbers or medical diagnostic codes, that are key to validating the code that relies on them. GenRocket makes it easy blend production data with synthetic data to maximize test coverage and identify software defects.GenRocket can generate synthetic data in the following database types and file formats:
-
- Volume: While masked production data is limited by the existing volume in a production data subset, GenRocket’s synthetic data masking solution offers nearly limitless data volume. A fresh data subset in the required volume can be generated for each test run, ensuring that developers and testers can perform each test with certainty that test datasets were not corrupted by previous test operations.
- No Limitations: Synthetic data masking removes the limitations of masked production data. It offers almost limitless combinations and permutations of data. It can handle data stubbing, negative and edge case data, 14 supported file types, multiple databases, and more. It enables the creation of a centrally managed library with hundreds or even thousands of reusable Test Data Cases that can accessed by remote teams to quickly generate 100% secure synthetic data. Changes can be quickly made to Test Data Cases, and the system can handle CI/CD pipeline integration with ease. When testing new systems, platforms, or interconnectivity among systems, GenRocket’s synthetic data masking offers far superior flexibility to masked production data.
With so many benefits, why do dev and test teams continue to work with masked production data on a daily basis? For most people the reason is simple – because they’ve always done it that way. Traditional data masking is a familiar process they’re accustomed to and comfortable with. And until now, there’s not been a better solution to take its place.
However, technologies advance and processes evolve. As a result, traditional Test Data Management (TDM) is gradually becoming more automated, operationally efficient, and seamlessly integrated with development tools and testing frameworks. TDM is evolving to become Test Data Automation – the ability to model, design, deploy and self-manage synthetic data for any testing purpose. Synthetic data masking is just one part of this evolution.
Once you understand the benefits of GenRocket’s approach to synthetic data masking, you’ll never look at masked production test data the same way again. If you would like to see synthetic data masking in action, just schedule a demo with one of our synthetic data experts.